数据分析之表达式语言:DAX
前言
计划整理有关“数据分析表达式语言”的系列文档,计划包括以下内容:
-
MDX(Multi-Dimensional Data Expression) 表达式语言
-
DAX(Data Analysis Expressions) 表达式语言
-
Tabula 表达式语言
在每一个数据分析产品的背后,必然有一个表达式语言,用于对一些复杂的业务分析,尤其是指标(Measure)进行表达,并提供一套优化的计算引擎, 达成对数据的快速分析。例如:
- 计算原始指标在查询结果中的排名、占比
- 计算原始指标的时间快速计算如:
- 同期值、同比增长、同比增长率
- 上期值、上期增长、上期增长率
- 年累积、月累积
- TopN 计算。
- 15大详细级别表达式中的各种计算。
在实际业务分析中,上述的这些分析需求其实是非常常见的,虽然这些都可以在 SQL 中进行计算,但即使是简单的排名、占比也会需要编写复杂的 SQL 语句,而且,复杂的 SQL 语句的可读性也是相当糟糕的。对复杂的 SQL 语句,其执行性能也未必是最佳的。
因此,一个表达式语言,主要就是承载如下目标:
- 计算的表达能力。尽可能具备有完备的计算能力,能够表达各种复杂的计算逻辑。
- 表达式语言的可读性、简单性。越高抽象的表达式语言,可以将复杂的计算逻辑简单化。便于用户理解、编写。
- 计算的高效性。毕竟,数据分析往往面对的是一个巨大的数据集,如果计算非常耗时,那么就不实用了。
DAX(Data Analysis Expressions) 表达式语言
DAX 是 Microsoft PowerBI 产品的表达式语言,也是 PowerBI 的产品灵魂。了解它的权威书籍是《The Definitive Guide to DAX》。
我对 PowerBi 并没有太多的实战经验,对其的理解主要是在设计数据分析产品时,经常需要对一些分析逻辑,参考 PowerBI 的概念时, 对 DAX 进行针对性的分析、揣测。
Power BI 中的筛选方向
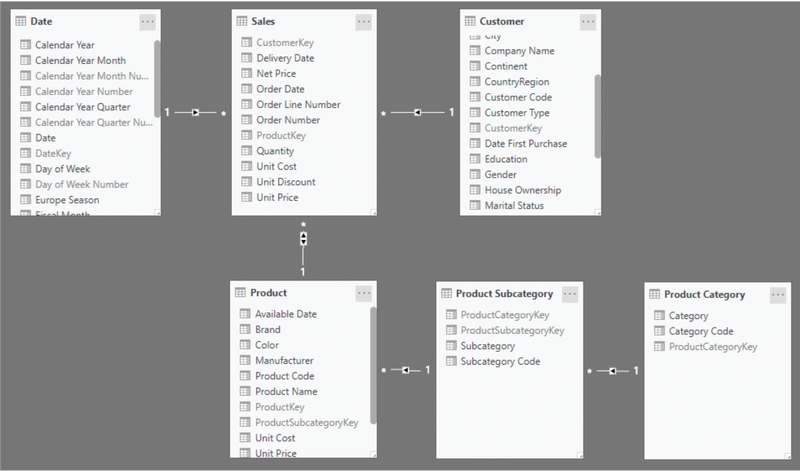 筛选方向是 PowerBI 中的一个重要概念:
筛选方向是 PowerBI 中的一个重要概念:
- 选定给定
日期时,按照上图,会自动的筛选:销售、产品,而不影响客户、产品分类的数据的可见性。 (上图中销售 和 产品)设置了双向筛选。 - 在多维查询时,维度就是筛选条件,作为结果,筛选出来的数据(多行)是一个结果集,在这个结果集上通过某个函数运算,得出的一个值 称之为度量(Measure)。所以,度量是一个集合上的函数,而维度则是这个集合的筛选条件。
- 一般的,维表 与 是事实表之间的关系是一对多的关系,即一个维表的一行对应多个事实表的行。 一个维度表的一行对应多个事实表的行,这个是默认的筛选方向。
- Power BI 支持双向筛选,即从多方向一方的筛选。与一方对多方的筛选不同(一个事实总是有唯一的维度值),多方对一方的筛选,意味着 一个事实的维度有多个值,例如:一个用户有多个标签,一个 SPU 可以有多个颜色。当你使用标签、颜色筛选用户、SPU时,就是多方对一方的筛选。
- 按照图示的方式,是比较好理解一个维表的影响范围(即其筛选的范围)、或者一个事实表的边界(即哪些维度会影响这个事实表的范围)
- 在模型中,并不存在那个表是维表、那个表是事实表的概念,维表和事实表是根据场景来确定的
- 销售与产品的双向筛选,意味着以销售为事实表是,产品是维度表,反之,以产品为事实表时,销售是维度表。
- 在PowerBI的模型图中,顺着箭头的方向(筛选方向),就是维表的影响范围,反之所有可以顺着箭头触达事实表的都是这个表的维表。
Filter Context vs Row Context
DAX 中有两种上下文:Filter Context 和 Row Context。 这个是很容易混淆的,或者错误使用的:
-
column reference and measure reference.
- column reference:
Sales[Quantity]or[Quantity]in Sales Context(比如在 Sales 表的计算列定义中) - measure reference:
[Sales Amount] - table reference:
Sales - column reference 与 measure reference 如果有歧义,怎么处理?DAX 会优先解析为 column reference
- column reference:
-
Filter Context: 用于对当前的数据范围进行筛选。
- Filter Context 是对整个模型有效的,如果有一个筛选条件
[table1].[col1] = value1, 那么,这个条件会筛选 table1 中满足条件的行, 并根据模型中的筛选方向,传递到其他表中。可以简单的理解,通过 Filter Context, 一个模型的数据可见范围被动态的调整了,这时,任何一个表中 的数据并不是原始表中的数据,而是经过筛选的数据。 - evaluation
table reference在 filter context 中求值measure reference在 filter context 中求值
- 创建/修改 Filter Context
- 在一个分析表格中,每个单元格都有自己的 Filter Context,一般由行,列,过滤器等决定。即使不同的单元格使用的是同一个计算公式,但由于 Filter Context 的不同,计算结果也会不同。
- 诸如 ALL, ALLEXCEPT, ALLSELECTED 等表函数,可以用于修改 Filter Context。
- ALL(table) 函数,清除 table 上的所有筛选器
- ALL(table, column) 函数,清除 table 上的除了 column 列的所有筛选器
- ALLEXCEPT(table, column1, column2, ...) 函数,清除 table 上的除了 column1, column2, ... 列的所有筛选器
- ALLSELECTED(table) 函数,清除 table 上的所有筛选器(动态的筛选器),但保留用户手动选择的筛选器(原始的筛选器)
- RelatedTable( table ) 将 当前 row context 添加到 table 的 filter 中。
- CALCULATE(expr, filter1, filter2, filter3) 函数,可以用于修改 Filter Context,并在新的上下文中计算 expr 表达式的值。
- boolean filter:
[column] = value - table filter:
filter(table, expr) - filter modifier:
- ALL、ALLEXCEPT
- REMOVEFILTERS(table, column*)
- KEEPFILTERS(expr) 保留当前的筛选器,但可以合并值,不同于 boolean filter,那个是替换筛选器。
- USERELATIONSHIP/CROSSFILTER -- 修改表筛选关系
- Calculate 会将当前的 RowContext 转换为 FilterContext。
- boolean filter:
- FILTER 函数自身并不修改 Filter Context, 而是生成一个计算表。作为 Calculate 的参数时,其会修改原始表的数据范围。
- 表函数是否有2种语义:其一代表一个表的数据,其二代表修改在这个表上的 filter
- Every measure reference always has an implicit CALCULATE surrounding it.
- 完成了将当前 Row Context 转化为 Filter Context,从而影响 Measure 的求值
- 两种 filter
- column filter: 更高效
- table filter: a calculated table
- Filter Context 是对整个模型有效的,如果有一个筛选条件
-
Row Context
- 创建 RowContext
- 计算列在 RowContext 中求值
- SUMX 等 iterate 函数会创建一个新的 RowContext
- column reference
tab[col]可以在 RowContext 中求值- 如果存在 1个
tab的 row context,则在其中求值 - 如果存在 多个
tab的 row context,则在 latest 的 row context 中求值 - 否则无法求值
- 如果存在 1个
- 在某个求值点,可能存在 0..N 个 RowContext 和 1 个 FilterContext。
- EARLIER(column, number) 函数,可以在 RowContext(-number) 中的 column 列的值
- EALIST(column)
- 每个 row context 的范围是模型中的单个表,不会扩展到其他表去
- Related(column) 与 row context 相关的 column,适合于 N:1 的关联字段
- RelatedTable(table) 与 row context 相关的 table,适合于 1: N 的关联。
- RelatedTable(table) 这里的 table 是否会受当前的 filter context 影响? Y
- RelatedTable(table) 这里是创建了一个新的计算表,还是更新了 filter context?
- Calculate 会将当前的 RowContext 转换为 FilterContext,并消除掉所有的 RowContext.
- 创建 RowContext
其实,一个比较好的方式,是注明 DAX 函数的每个参数的求值上下文,是 Filter Context 还是 Row Context,这样就可以让这个概念 更为清晰了。毕竟,只有少数的函数会创建新的上下文,大部分的函数都是在已有的上下文中进行计算。
TODO: 举例说明(补充一个例子,可以看到 哪些是在 Filter Context 中计算,哪些是在 Row Context 中计算, 以及如何通过 CALCULATE 函数,创建新的 Filter Context。) 示例1:
-- 在 SUMX 的 caller 中,有一个 Filter Context,这里假设为 fc0, 也可能有其他的 Row Context,这里假设为 rc0
SUMX (
Sales, -- 在 fc0 中计算表
Sales[Net Price] * 1.1 -- SUMX 函数会生成一个RowContext,这里假设为 rc1, 这个表达式的求值上下文为: fc0 + rc0 + rc1
-- Sales[Net Price] 会在 rc1 中求值。
)
示例2:
-- fc0 , rc0
SUMX (
'Product Category', -- eval in fc0, and will create new Row Context rc1 for each row in 'Product Category'
-- 对 'Product Category' 中的每一行创建一个 Row Context: rc1
SUMX ( -- eval in fc0 + rc0 + rc1(Product Category)
RELATEDTABLE ( 'Product' ), -- eval in rc1
-- 对每一行 Product, 创建: rc2(Product)
SUMX ( -- eval in fc0 + rc0 + rc1(Product Category) + rc2(Product)
RELATEDTABLE ( Sales ) -- eval in rc2(Product)
-- 对每一行 Sales, 创建: rc3(Sales), 上下文为: fc0 + rc0 + rc1(Product Category) + rc2(Product) + rc3(Sales)
Sales[Quantity] -- eval in rc3(Sales)
* 'Product'[Unit Price] -- eval in rc2(Product)
* 'Product Category'[Discount] -- eval in rc1(Product Category)
)
)
)
上面的这个表达式可以简化为:
SUMX (
Sales,
Sales[Quantity] * RELATED ( 'Product'[Unit Price] ) * RELATED ( 'Product Category'[Discount] )
)
Filter Context 与 MDX 的异同
在 MDX 引擎中,Filter Context 的概念是非常相似的,一般的, MDX 的 filter context 由一下几个部分组成:
- Filter axis:在 WHERE 子句中的筛选条件构成了 filter axis
- Column axis/Row axis: 在 SELECT 子句中的列、行构成了 Column axis/Row axis
- 在 MDX 中,可以通过
[Dim1].[ALL Dim1s]等语法手动的设置某个维度的筛选条件,改变其筛选条件。
总的来说,DAX 的 Filter Context 相比 MDX 来说,要复杂的多,当然,也要强大的多,灵活的多,或者在很多场景下,也会有更好的性能:
- MDX 是 多维模型,一个 MDX 就是一个N维多维空间。 而 Power BI 是表-关系模型,每个事实表(根据其筛选关系构建的一个查询子图)都是一个 独立的多维空间。 DAX 更可以动态的创建计算表,因此,灵活性就更大了。
- DAX 的 filter context 中, 分为 column based 的 table based,其中 column based 的 filter 是满足 SQL 下沉的 基础的,这样在数据库上执行时,会有更好的效率。 MDX 理论上也可以如此,目前的开源引擎 mondrian 在这方面做得不够,可以参加我整理的 MDX optimize 一文
- MDX 对 filter context 的修改能力也较弱,不过这个理论上是可以通过 MDX 的函数来实现的,不算是引擎的问题。