MDX 执行引擎优化思路 ...
EvaluationContext 优化
- AllMembers
- Member(u32) -- native member
- CalcMemberInCube(u32)
- CalcMemberInQuery(u32)
- SlicedMembers -- 全局的 slice 筛选,会同时跨多个维度
- FilteredMembers(u32) -- 单维度的筛选上下文
- ReservedLevel(u32) -- pseudo
- _ReservedOther(u32) 通过扩展 MemberFilter 的能力,支持更好的 filter pushdown 能力。解决目前,不能有效或正确的下沉。
当 MDX 查询中涉及到 filter 轴时,如果简单的展开集合,filter 集合会放大 MDX 的计算。 例如: filter 集合 为 1000 时,会导致每个 cell 的计算都会进行1000次的计算。
优化1: slice
当 filter 集合不是一个正交集合时,会在 Context 中保存为 sliced: Set[Tuple]
- 如果当前 Context 中 filter 的所有维度,其值为 SlicedMembers 时, 会将完整的集合下沉。
- 如果filter轴中部分维度的值为 SlicedMembers 时,会根据这些维度,生成一个新的下沉条件。
优化2: 保存为 多个 FilteredMember。
filterMember 会直接传递到 cellRequest,而无需展开。
下沉按需展开
当计算 expr 时, 在表达式中,需要获取 dim1 维度的当前值进行计算时,而这个维度在 slice 或 FilterMember中时,需要对其展开:
此时, slice 和 filter 仍然会传递到 cellRequest 中 (计算度量 与 计算成员的优先级问题,需要有 expr 的再聚合方式)。
filter 函数优化
尝试将 filter 函数优化成为支持如下能力的函数,可以快速执行一个 tuple load.
- loadTuple 函数设计方案,能尽量下称到 SQL 执行
优化相关
- member cache
- tuple cache
- segment cache
- compute cache
- 公共表达式消除
- batch-fetch buffer optimization
- profile support
- 向量化优化
segment cache
-
Cell Request
// 存储 查询生命周期相关的信息, slice, filter 信息可以在这里保存 struct QueryContext { } // 存储 模型模型生命周期相关的信息,例如 member 可以在这里进行 cache struct CubeContext { } struct EvalContext { members: Vec<MemberValue>, slicer: Slicer, } struct CellRequest { members: Vec<MemberValue>, pattern: BitMap, // 1: equals for AllMember, SlicedMember, FilterMember, 0: same shape for PrimaryMember, HierarchyMember } enum MemberValue { AllMember, SlicedMember(&Slicer), // 在 slice 中指定 PrimaryMember(usize), // 对应于非层次维度下的一个基础成员(sql 绑定单个字段) HierarchyMember(usize), // 对应于层次维度下的一个成员(sql 绑定多个字段) FilterMember(&Filter), // 对应于一个 filter member, 例如 it > '2023-01-01' and it < '2023-12-31' CalcMember(&CalcMember), // 对应于一个计算成员, 在 CellRequest 中,不会出现 } // MemberValue 可以编码为 MemberValue16, MemberValue32 trait CellRequestBuffer { fn cellRequest_exists(&self, request: &CellRequest) -> bool; fn add_cellRequest(&mut self, request: &CellRequest, value); } trait SegmentLoader { fn load(requestBuffer: CellRequestBuffer) -> Segment; } trait Segment { fn cellRequest_matches(&self, request: &CellRequest) -> bool; fn get_cell(&self, request: &CellRequest) -> Option[Value]; }- MemberValue16 bit0: 0: 1: ALL(0)/PrimaryMember(n) 最多可表示 32K 成员 bit1: 1: 10_b13 SliceMember(0)/FilteredMember(n) -- 最多 16K 个切片成员 11_b13 CalMember(n) -- 最多 16K 个计算成员
- MemberValue32 做多可表示 2^31( 2G 个成员 )
在一个查询中,可能会构造当量的 CellRequest, 且出现重复请求的情况很多,因此,需要一个非常高效的 hashmap 来进行缓存。
- MemberValue 尽可能编码为 i16/i32, 减少内存占用,并且机制 hash 计算。
- cellRequest 以 trait 设计,提供几个精简的实现,最小化内存使用:
- CompactCellRequest32: 32 字节大小, 最多支持 15个 维度, 每个 member 支持 2字节编码或 4字节编码。 pattern 使用 2 字节。 其中 2字节可表示 2^15 个 成员(Slice/Filter/ALL 保留若干成员), 可处理大部份的小维度。 4字节可表示 2^31 个 member。
- CompactCellRequest64: 64 字节大小,最多支持 30 个 维度。 bitmap 使用 4字节。
- CompactCellRequest128: 128 字节大小,最多支持 60 个维度。 bitmap 使用 8字节。
- CellRequestN: 支持任意的维度数量,但是内存占用较大,不适合大部份的场景。
结合 Rust 的 HashMap 实现,可以实现一个高效的缓存:
- 存储结构紧凑,内存使用少
- hash 效率高
- 内存连续性好(大部份的 CellRequest 是一个纯值对象,没有二次引用)
- 结合 HashMap 的 SIMD 实现,查找效率高
- cell request 是从 Context 演变来的,需要设计 Context 的存储机制,使得这个转换几乎0成本
与 Java实现对比:
- RolapEvaluator 可以通过 savepoint/restore 机制来实现共享一个 evaluator, 以节省内存使用。更换一个 member 需要在 history 中增加 SET_CONTEXT index member 3个对象, 至少24字节,当有2-3个字段更新时,这个成本还不如直接创建一个新的 Context 轻量
-
Expr cache 当 EvalContext 中包括至少1个计算成员时, 可以对 Expr 进行缓存,以减少计算成员的计算成本。
对当前 MDX, 每一个 AST node 都可以生成一个 计算度量,有一个查询级的 ExprId,以及 Expr 的依赖维度列表。 eval(Expr)时, 会根据 (ExprId, EvalContext.with(expr.dependencies)) 来查找缓存。
不是所有的 Expr 都会进入这个缓存,一般的,系统中部分 expr 会根据规则,进入这个缓存。可以在 MDX 中使用特殊的函数来控制这个规则。例如:
(/*expr-cache*/ expr ) -
segment cache
-
可以在多个 MDX query之间共享 segment cache.
key: (cubeId, cubeVersion, shape, CellRequestCrossJoin): cubeId cubeVersion: 每次抽取后,cubeVersion + 1 shape requests: 仅对 CrossJoin Bag 进行缓存,存储各个维度的 值 value: SegmentData( HashMap[ compact_cell_data, Value] )segment cache:(or using rocksdb as storage.)
- in memory
- in files
1个shape 可能对应多个 Segment, 是否需要进行合并。
-
自动的 aggregation 对宽表进行查看时,可以识别每个查询使用到的维度,预先按这些维度进行聚合。再在聚合后的结果上进行查询。
-
求值优化
-
公共表达式提取
关于公共表达式提取,有两种方式:
- 简单提取:如果两个 AST 结构相同并且具有相同的类型,则可以共享同一个 AST tree。 evaluate( tree1, context ) 完成后,可以将 contetx 和 value 保存到 tree中。当再次执行这 evaluate 时,如果 context 没有变化,则无需重复计算。
- 优化提取:当前仅当检测到 两个 AST 会共享同一个 context 时,才共享同一个 AST Tree。 做一个改写, 在 第一个 AST 中, 改写为 { val x = ..., x },后续直接引用 x 即可。
-
表达式是调用者求值,还是函数求值。
- 可以标记 函数的参数,是否可以由调用者求值(在调用者的 context 中),还是由函数求值,如果由函数求值,则函数可能会改变 context。 进行这个标记,可以帮助进行公共表达式的提取优化。
-
表达式相关维度。 部分的 tree,求值时,仅引来 context 的部分维度,这时,即使context 的其他维度发生变化时,其值仍然不变。 将这个 mask 存储在 tree 中,则求值的时候, 可以更好的进行优化。
class Expr: val mask: Set[Dimension] = Set.empty var lastContext: Context var lastResult: Value def evaluation(implicit context) = if context == lastContext then lastResult else val depContext = context.keepOnly(mask) // 清理无关维度 cache[depContext] match case x => x case _ => realyEvaluation(context)
对函数的参数,可以分为3类:
-
在 caller context 中提前求值。
-
在 caller context 中延迟求值。(例如 iif 函数)
-
在 callee context 中求值。(例如 filter 函数的 conditional)
-
在一个表达式求值时,如果求值 f(a, b, c),在 caller context 中求值的表达式可以进行 公共表达式提取,这个过程可以递归向下。
-
如果两个表达式完全相同,但可能运行于不同的 context, 则可以按 (mask, mask(context)) 进行cache。
-
由于伪求值阶段的存在,对 pseudo value 是否 cache? 如果不 cache,则在伪求值阶段会重复计算。如果 cache,则什么时候清理掉这个 cache。
批量加载
在 MDX 执行过程中,会涉及到 loadCell 的调用,简单加载模式中,每次 loadCell 都会发起一个SQL语句,并 同步等待结果返回, 这种方式实现简单,但由于一次查询过程中,这样的 loadCell 会发起上百次,上千次,乃至上百万次,上千万次, 会存在很严重的性能问题。
优化方案:
- 执行过程中,requestCell 并不真实发起请求,而是将其放入到一个buffer中,并返回一个 pseudo value 同时增加一个 dirtyCount.
- 如果表达式计算过程中,dirtyCount 没有增加,则这次计算时有效的,可以直接作为返回值,并进行 cache。 否则这个返回值也是一个 pseudo value,不能进行 cache.
- 在计算结束后,将 buffer 中的 requestCell 进行批量处理,发起一个 SQL 请求,保存查询结果,并重新发起计算, 直到 dirtyCount = 0 为止。
每个批次,对应于一个 SegmentLoad,他可能返回超过请求 cell 数量的结果.
def cellRequest( cell: CellRequest):
cellCache.get(cell) match
case x => x
case None =>
cellRequests.add(cell) // also increase dirty
PseudoValue
class CellRequestBuffer:
var dirtyCount: Int = 0
def add(cell: CellRequest): Unit
CellRequestBuffer 会按 cell 的 pattern 进行分组记录, 具备一下特性的 cell 可以归入统一分组:
- 如果 cell1.dim1 的值 为 ALL, 则 cell2.dim1 == cell2.dim1
- 如果 cell1.dim1 的值 为 PrimaryMember, 则 cell2.dim1 也是 PrimaryMember(两者值不一定相等)
- 如果 cell1.dim1 为 HierarchyMember, 则 cell2.dim1 也是 HierarchyMember(两者值不一定相等)
- 如果 cell1.dim1 为 FilterMember,则 cell2.dim1 == cell1.dim1
- 如果 cell1.slice 不为空,则 cell2.slice == cell1.slice
由两种方式可以组织 buffer:
- List[CellRequest] 这种方式保存的数量一般会限制在 1000 以内
对应的SQL 为:
SELECT d1, d2, d3, SUM(m1) from cube where (d1, d2, d3) in ( (v1, v2, v3), (v4, v5, v6) ... ) and (f1 > f1_0 and f1 < f1_1) -- filter field and (s1, s2, s3) in ( (s1_0, s2_0, s3_0), (s1_1, s2_1, s3_1) ... ) -- slice - Map[ Dim, Set[Member] ] 当 List[CellRequest] 达到一定值时,调整为这个结构。
对应的SQL 为:
后者对应的 segment,可能会返回超过请求的数据,可以匹配更多的 cellRequest 请求。SELECT d1, d2, d3, SUM(m1) from cube where d1 in (...) and d2 in (...) and d3 in (...) and (f1 > f1_0 and f1 < f1_1) -- filter field and (s1, s2, s3) in ( (s1_0, s2_0, s3_0), (s1_1, s2_1, s3_1) ... ) -- slice
YTD, MTD 等窗口类函数的计算优化。
典型的,例如计算 stdev 聚合方式时,可以参照 《Efficient Processing of Window Functions in Analytical SQL Queries
》 论文中的优化方式,极少计算量。
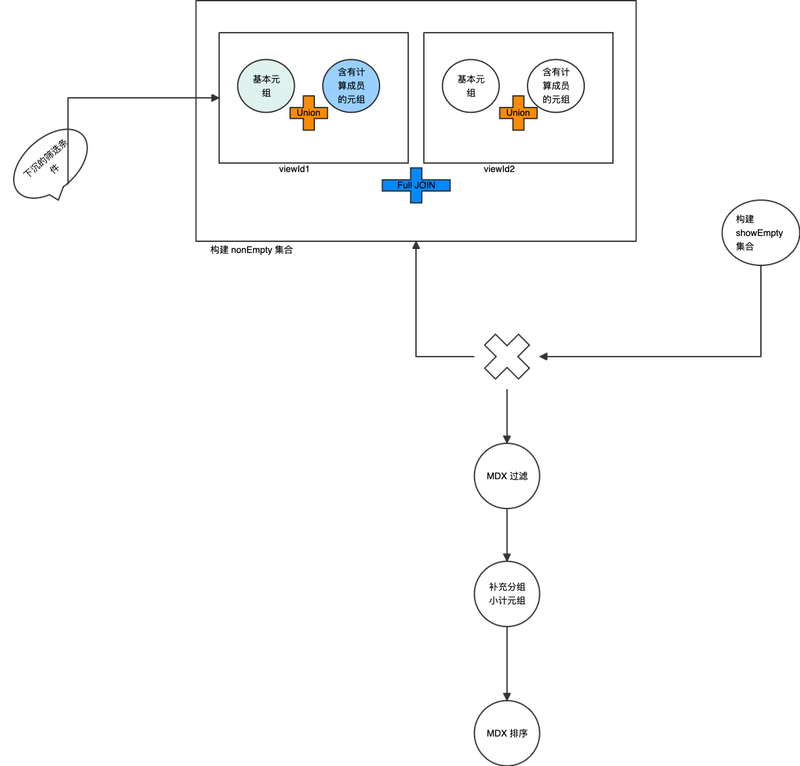
LoadTuples 函数定义
多维查询时,基于事实表的 tuples 会比 crossjoin 有多个数量级上的下降,而在多事实情况下, nonEmptyCrossJoin 的语义并不清晰,因此,
我设计了新的 loadTuples 语义:
loadTuples(
"dimension:", [Dim1], [Dim2], [NS1], ..., // 元组中使用的维度,是否支持显示给定层次?
"showEmpty:", true, false, false, ..., // 各个维度是否容许显示空成员,命名集也可以考虑支持 showEmpty
"showSubTotal:", false, true, false, ..., // 各个维度是否显示小计,命名集明确不支持小计
"dimensionContext": null, ([Dim1]), null, ..., // 显示空成员时维度的筛选上下文,或许可以省略,从Schema中可以获得。
"where:", boolean-expression, // 筛选Bool表达式
"sorts:", expr1, expr2, ..., DESC|ASC|BDESC|BASC // 排序设定
"viewIds:", viewId1, viewId2, ... // 从那些事实表中加载维度组合。
)
说明 新定义的 LoadTuples 函数比较复杂,综合了如下的能力:
- 显示空成员的维度:在 showEmpty = true 中指定需要显示空成员的维度,其他为不显示空成员的维度。(目前仅支持显示空成员的维度之间的筛选, 不显示空成员的维度不参与显示空成员的维度的筛选)
- 不显示空成员的维度
- 分组小计。(对单层次维度,创建 aggreate 计算成员 或者映射到 All , 对多层次维度,如果该维度有过滤,则使用 VisualTotal 函数)
- 多事实表逻辑。 当选择 viewId1, viewId2 等多事实表时,维度组合符合如下逻辑:
- 如果 viewId1 包含的轴上维度(D_i, D_j, D_k) 与 viewId2 的轴上维度一致时, 二者是一个 union 关系(去除重复)
- 如果 viewId1 包含的轴上维度(D_i, D_j, Dk)是 ViewId2 (D_i, D_j, D_k, D_l)的子集时,如果 (D_i, D_j, Dk)组合在 (D_i, D_j, D_k, D_l) 中已存在,则不再重复出现。
- 否则同时包含viewId1的元组和viewId2的元组。
- 筛选能力:
- 对维度值进行过滤的筛选条件可以直接下沉(包括WHERE区的条件)
- 使用基本度量作为过滤条件,与元组的部分维度相关,可以考虑使用窗口函数 + having子句进行下沉
- 更为复杂的计算度量暂时不能下沉,在 MDX 引擎中执行。
- 排序能力:
- 可以对维度值进行过滤(下沉)
- 可以对基本度量(与部分维度相关),可以考虑使用窗口函数 进行下沉
- 更为复杂的计算度量暂时不能下称,在 MDX 引擎中执行。
预期的优势:
- 新的 loadTuple 函数基本涵盖了目前仪表盘构建轴上元组的大部份能力(并在排序上有所超越)
- 对多事实的处理、筛选能力、排序能力有更好的下沉能力,可以获得更好的查询性能。
- 即使考虑到复杂的Where条件,loadTuple仍然有更好的下沉能力,在下沉SQL的基础上,再结合不能下沉的 filter + sort 处理,整体性能会比现有的不能下沉的场景有更好的性能。
- 对比现有的 crossjoin / nonEmptyCrossJoin/ dim.members,有更为清晰的查询语义,便于整个查询的质量提升
Where 轴上的条件,在多事实表情况下,需要进行的处理逻辑包括:
-
如果 viewId1 不包含 dim1, 则在 WHERE 条件应用到 viewId1时,需要对 Bool 表达式进行如下的改写:
- 如果 表达式 dim1.currentMember oper literal 使用了viewId中不存在的字段,这个表达式改写为 UNUSED
- UNUSED and any --> any
- UNUSED or any --> any
- NOT UNUSED --> UNUSED 最后逐步的进行化简,如果最后化简的表达式不包含 UNUSED,则可以直接下沉。如果化简后为 UNUSED,则化简为 true.
-
计算成员 在不显示空成员时,如果维度有计算成员,则在 LoadTuples 中需要补充计算成员。 (D_1, D_2, D_3, ..., D_n)中,如果 D_2, D_3有计算成员,则需要补充成员:filter( { (D1, D4) } * { D2.calcMembers, D2.calcMemers }, [Measures].[Fact Count] > 0 )
-
筛选条件下沉 以 f1 && f2 && (f3 || f4) 为例, f1 , f2 可以独立下沉, f3 || f4 只能作为整体下沉,具备下沉的 bool 表达式 f 满足:
- f 是 TOP 层的自成员,且 TOP 层的各个自成员之间是 and 关系。
- f 形如 dim1.currentMember.caption operate constant 且 dim1 在不显示空成员中,则 f 可以下沉
- f 形如
[Measures].[X]operator constant 且 X 是基本度量,则 f 可以下沉 - f 形如 (
[Measures].[X], [Dim1].[All Dim1s]) operator constant 且 X 是基本度量,则 f 可以下沉。 - f 是2 AND (3 与 4的组合),则 f 可以下沉。
具备下沉条件的表达式将在如下环节执行:
- 非空基本元组(非计算成员)在 SQL 中执行
- 如果该字段有计算成员,且显示计算成员,则在补充计算成员的元组前,进行过滤。
- 新增分组小计的元组,在新增前,进行过滤。 不具备下沉条件的表达式,统一在最后的 MDX 过滤阶段进行过滤。
-
计算元组时,自动携带辅助的计算(可用于MDX过滤阶段、MDX排序阶段) 在计算元组的值时,可以附带计算用于后续处理所需的值,例如 filter, order-by。 在 MDX 过滤阶段,对给定元组,如果需要对特定值进行求值,可以使用 tuple.properties.get( expression ) 先获取值,如果已有值的话,则无需额外求值。