Yedis:一款轻量级、高性能的Redis驱动程序
Redis是互联网应用中广泛使用的缓存解决方案,以其高性能、丰富的数据结构、简单易用的API而著称,基本上已经成为了互联网应用的基础设施, 其重要程度与MySQL、Nginx等足以相提并论。Jedis是最常用的Redis Java驱动程序,在我们的应用中也广泛使用Jedis驱动程序。
在使用Jedis的过程中,我们遇到了如下的问题:
-
Jedis 对 Redis Cluster 支持有局限,Slave实例不能提供读访问。诸如MySQL的Slave实例,一般用于承担一定的线上只读访问访问, 以降低对主库的访问压力,提高整个系统的吞吐能力。虽然Redis实例具有很高的访问性能,单实例可以提供10万量级的访问QPS, 但也是存在上限的。对电商、秒杀等业务场景,单实例的处理能力仍然会成为性能瓶颈,既然 Redis Cluster 支持 Master/Slave 模式, 为什么不能充分应用 Redis Slave 来分担访问压力呢?
-
Jedis 使用连接池的模式,在实际应用中,就需要关注诸多的连接池参数,并尝试平衡:
- minIdle
- maxTotal
- maxIdle
- testOnBorrow
- testOnReturn
- testWhileIdle
- timeBetweenEvictionRunsMillis
- numTestsPerEvictionRun
本文并不尝试介绍最佳的 Jedis 参数实践,这些参数的调优过程确实是一个挑战。当服务部署的实例增加到一定量级后,配置一个较大的连接池, 会导致单个redis服务实例需要支持一个很大的连接数。这些也给到DBA一定的心理压力。
-
Jedis 连接需要 testOnBorrow, 或者testOnReturn 等检测机制来检测连接状态是否正常,这种检测或者会导致额外的 RTT 时间, 从而降低了应用的访问速度(每次连接0.1ms级别)。或者采用 testWhileIdle 机制,这种机制避免了每次连接进行测试, 但无法保证连接检测的及时,有可能出现漏检的可能型。
-
在 Redis Cluster 模式下,Redis服务并不支持 mget, mput 等批量操作。而业务上碰到这类场景时,或者采用串行模式逐个调用 get 操作, 或者使用线程池等方式,进行并发操作。无论哪一种方式都不够让人满意:串行的性能不佳,多线程的模式,由增加了业务服务的复杂性。
基于如上的痛点问题,我们决定自研一个匹配的驱动程序,我们称之为:Yedis,可以理解为 Yunji Redis Driver 或者 Yet another Redis Driver。
Yedis 使用说明
-
maven依赖
<dependency> <groupId>yunji.yedis.client</groupId> <artifactId>yedis</artifactId> <version>1.3.2</version> </dependency> -
基本API用法
//初始化
Yedis yedis = new Yedis("172.16.0.3:6379,172.16.0.3:6380", 5);//超时时间(单位:秒)
//String
yedis.set("key_str", "test_value");
String val = yedis.get("key_str");
//Hash
Map<String, String> map = yedis.hgetAll("key_map");
List<String> list = yedis.hmget("key_map", "f1", "f2", "f3");
String str = yedis.hget("key_map", "f1");
//List
List<String> list = yedis.lrange("key_list", 0, -1);
List<String> list = yedis.sort("key_list");
yedis.rpush("key_list", "1", "2", "5")
//指定数据读取来源
yedis.get("key_str", ReadModel.MASTER_SLAVE);//ReadModel:MASTER、SLAVE、MASTER_SLAVE
//Pipeline
Pipeline pip = yedis.openPipeline();
pip.set("key_string", "a"); //返回值:String
pip.hvals("key_map");//返回值:List
pip.get("key_map");//数据类型不匹配,异常
pip.zrangeWithScores("key_zset", 0, -1);//返回值:Tuple
List<Object> list = pip.getResults();
for(Object obj : list){
if(obj instanceof YedisException){
YedisException exception = (YedisException) obj;
exception.printStackTrace();
}
System.out.println(obj);
}
- JMX 监控 yedis提供监控信息方便查看当时运行状况,以及基本的统计信息:
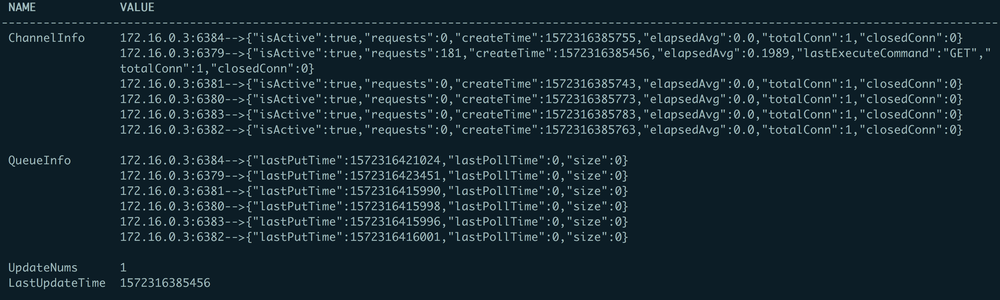
监控中包含4个属性:
- ChannelInfo:一个redis节点对应一个channel,监控中可以看到当前连接是否正常、当前连接创建时间、请求数(最近20s内)、平均响应时间(单位:ms)以及该Redis节点对应的连接总创建、关闭次数
- QueueInfo: 记录Queue最后一次写入、消费时间、Queue中消息阻塞数(Queue的具体作用下文会提到)
- UpdateNums: Reids集群发生变更次数
- LastUpdateTime: 最后一次更新Redis状态时间
基本架构图
Yedis 采用了如下的设计思路:
- 每个 Redis 节点只维护一个连接,所有的客户端线程均共享单个连接,发送命令。而不采用连接池。
- 基于 Netty,所有网络处理采用异步、非阻塞模式。
采用单连接模式是否会有性能问题?
- 单连接并不意味着一次只能有一个客户端请求redis,其它的客户端必须等待这个请求返回后,才能发起下一个请求。相反,Yedis在单个TCP Socket之上,多个应用线程可以并行的使用这个Socket发送命令。这个是基于Redis的Pipeline特性。
- 大部分单个的Redis命令执行时间非常之快,一般在 10-50us 数量级上,相反,即使在局域网上,网络的 rtt 一般也会达到0.3ms - 1ms量级。也就是说,如果从单个命令的执行过程来看,只有5%-15%的时间是在真正的耗费在redis执行之上,其余时间其实是耗费在等待网络传输的过程之中。
- 通过使用Pipeline技术,无需等待上一个命令处理完毕,再发送下一个命令请求,而是客户端一个接一个的将命令发送给Redis服务器,Redis逐个进行处理,再逐个的进行返回,客户端在逐个的处理返回结果。这种方式,可以实现单个连接就可以替代原有连接池才能完成任务。
那么单连接的模式是否会存在性能瓶颈呢?理论上确实有,在单个Socket上传输的最大速度 = windowSize / rtt,在万兆局域网下,这个值一般在50M byte左右。考虑到单个客户端对redis的访问很少会达到如此高的场景,因此,单个TCP连接的数据传输瓶颈并不会成为实际的问题。
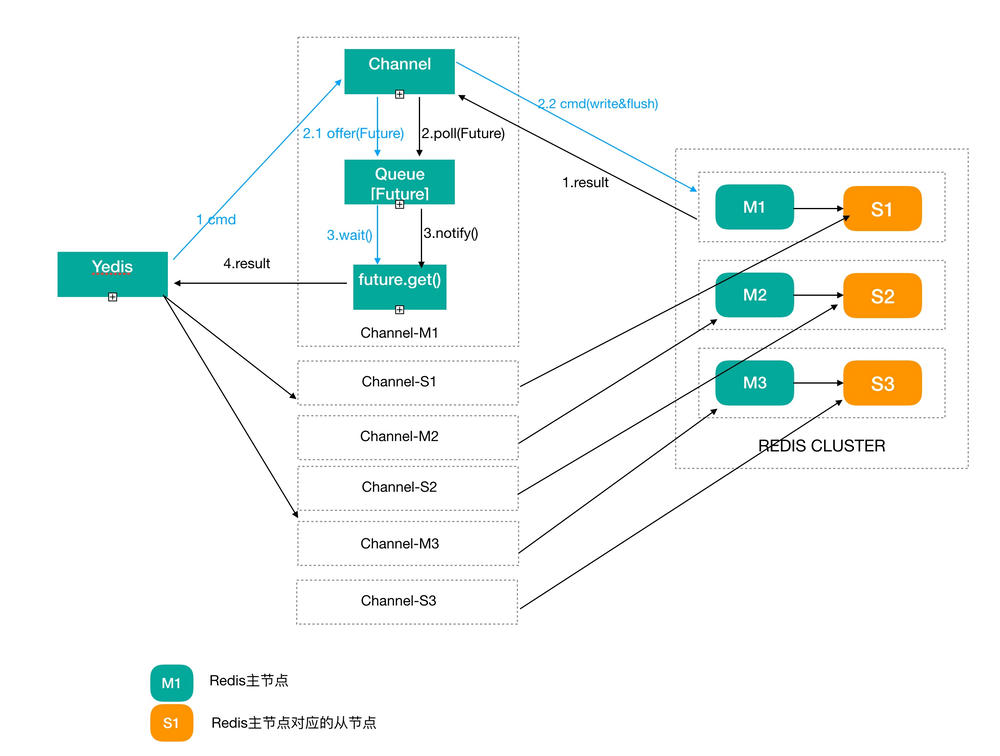
基本流程:正常命令处理
- 首先,根据用户所传入的Key进行计算,得到该Key的所在Redis节点对应的Channel
- 对选中的Channel,同步的执行如下操作:
- 创建一个处理返回结果的 Future, 保存到 channel 对应的队列中(目前没有使用JDK8的Future API,原因是需要提供对JDK7的API兼容)
- 调用 Netty writeAndFlush 操作将命令发送给服务器。 这两个操作必须同步完成,确保 queue 中的Future顺序和发送顺序完全一致,这样在下一步处理返回结果
private <R> R send(final Request request, Channel channel) { assertChannelNotNull(channel); ResponseFuture<R> future = new ResponseFuture(new SendCallback() { ...... }); synchronized (channel) { assertChannelIsActive(channel); try { YedisHandler.put(channel, future); channel.writeAndFlush(request); } catch (InterruptedException e) { throw new YedisInterruptedExceptionException(e); } } return waitResponse(future); } - Netty接收到Redis的返回结果后,从对应Queue中取出ResponseFuture,将结果设置到到ResponseFuture,然后唤醒客户端等待线程、将结果返回。
@Override public void channelRead(ChannelHandlerContext ctx, Object msg) { ResponseFuture response = take(ctx.channel()); response.setContent((RedisMessage) msg); synchronized (response) { response.notify(); } }
在上述的代码中虽然有 synchronized 代码块,但是,在代码块内没有阻塞性的操作,因此,其对并发的性能影响是非常微小的。当然例外也是存在的:我们会控制单个queue的排队数量,目前缺省是200,相当于最多可以有200个处理中的命令,对应于Jedis的话,相当于最多200个连接池。
基本流程:路由处理
- 先对Key进行CRC16、对16384进行取模,得到该Key对应的slot
- yedis内存中维护了一个长度为16384的slots数组,slots数组存储了Partion引用,Partion与Redis节点一一对应、同时也保存了Redis的主从关系。通过第1步的slot + ReadModel可以获得对应的Partion,进而获取对应的Redis节点Host
- yedis在初始化的时候,会为每个Reids节点创建一个channel连接,同时将channel缓存到本地Map,使用host作为key。通过第2步获取到的host便可从channel map中获取对应的channel,然后进行数据的发送了,
基本流程:网络异常处理
- 服务器异常关闭连接 yedis网络通信采用netty,与Redis保持长连接,一旦某个Redis节点连接被关闭,客户端能迅速检测到并且移除该Channel缓存信息,使得发往该Reids节点的请求在客户端便快速失败,不会因此堵塞;同时后台线程会异步的尝试重新创建到该Reids节点的Channel连接。
- 集群发生变化 yedis启动的时候,后台会启动一个异步线程,每5s检测Reids集群是否发生变化,例如:主节点down机、主从发生切换、新增/缩减Redis节点等,yedis会重新执行一次初始化操作,期间所有读写操作均暂停,直至Redis信息同步完成
基本流程:心跳检查
yedis后台有一个异步线程,每10s向服务端发送一个PING命令然后带上当前时间戳,然后我们检测Reids服务的返回内容是否与我们发送的时间戳一致,如果不一致,那就说明消息在Queue中发生了错位,我们会立即关闭该channel,然后立即重新创建一个新的连接
Pipeline 处理流程
yedis的数据发送、接收模式非常友好的支持Pipeline,是全局的Pipeline,而非针对某个Redis节点的。具体使用方式,可参考API基本用法。Pipeline处理流程十分简单,和普通命令唯一的区别就是同步和异步等待结果,Pipeline模式下,命令均返回ResponseFuture,在命令全部发送完成后,再统一等待结果。这样,Redis命令可以不停的发送到Redis服务端,而不必等待上一条命了处理完,再处理下一条,大大提升效率! 基于 Yedis 的单连接、异步处理框架,Pipeline的实现逻辑非常简单:
private <R> ResponseFuture<R> send(final Request request, Channel channel) {
assertChannelNotNull(channel);
ResponseFuture<R> future = new ResponseFuture(new SendCallback() {
......
});
synchronized (channel) {
assertChannelIsActive(channel);
try {
if (!YedisHandler.put(channel, future, timeout)) {
throw new YedisException(String.format("put msg to blockingqueue timeout %s seconds", timeout));
}
channel.writeAndFlush(request);
} catch (InterruptedException e) {
throw new YedisInterruptedExceptionException(e);
}
}
return future;
}
Yedis 性能测试数据
| 序号 | 线程数 | 测试数据大小(byte) | queue size | 主/从 | 总请求数 | 成功数 | 失败数 | QPS | YGC | FGC |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 16 | 256 | 200 | M | 320万 | 320万 | 0 | 64878 | 7 | 0 |
| 2 | 32 | 256 | 200 | M | 320万 | 320万 | 0 | 76591 | 7 | 0 |
| 3 | 64 | 256 | 200 | M | 320万 | 320万 | 0 | 82486 | 8 | 0 |
| 4 | 128 | 256 | 200 | M | 320万 | 320万 | 0 | 88704 | 8 | 0 |
| 5 | 256 | 256 | 200 | M | 320万 | 320万 | 0 | 81655 | 8 | 0 |
| 6 | 16 | 1024 | 200 | M | 320万 | 320万 | 0 | 55200 | 10 | 0 |
| 7 | 32 | 1024 | 200 | M | 320万 | 320万 | 0 | 63713 | 10 | 0 |
| 8 | 64 | 1024 | 200 | M | 320万 | 320万 | 0 | 68154 | 11 | 0 |
| 9 | 128 | 1024 | 200 | M | 320万 | 320万 | 0 | 74609 | 11 | 0 |
| 10 | 256 | 1024 | 200 | M | 320万 | 320万 | 0 | 71428 | 11 | 0 |
其它经验总结
在Yedis开发中,我们非常关注代码的性能,尽可能提供一个足够高效的驱动程序,这里简单的补充说明一下:
- 直接在 ByteBuf(一般的,是HeapOff的ByteBuf,可以提供更高的数据读写、分配性能)中搜索CR、LF等分隔符,实际测试表明:使用 ByteBuf.forEachByte 迭代相比手写的 for循环遍历,具有10-20%的性能提升。
- 最小化内存分配,减少GC负担。Yedis针对网络通信,尽量避免创建额外的对象。我们为每个Channel准备了一个缺省1024的buffer,除非单个redis响应字符串超过1024,否则无需额外的内存分配。这对于大量以较小的key,value为主的Redis应用来说,可以最小化对象分分配。
- 使用 immutable 的数据结构,简化并发情况下的线程安全。Yedis中涉及到大量的并发操作,这些并发操作会涉及到复杂的数据同步。同步操作是并发的万恶之源,为了简化并发处理,提高系统的鲁棒性,Yedis在存储共享的数据结构时,尽量采用 immutable 的数据结构,这个可以参考:
ClusterInfo、Node、Partion等数据结构。