数据库查询优化相关技术收集 ...
优化策略 Summary
每一个章节都可以写若干论文
- Expression Rewriter
- Filter Push-down
- Join
- 算法选择: Hash(parallel, grace), Sort(full, partial),
- 表顺序
- filter push-down
- Subquery as Join
- 子查询的查询优化: Executor -> Evaluator -> Executor 的执行模式是非常低效的
- Calcite 中新增的 Top-down 优化器
- Window 函数优化
- 窗口:重用窗口、增量式窗口
- 聚合:增量式聚合
- group-by + 聚合函数优化
- 分区: map-reduce
- avg() 转换为 SUM()/COUNT()
- 消除 grouped dataframe
- 减枝
- 裁剪列
- 裁剪表(关联)
- 索引优化
- minmax
- bloom
- bitmap
- sorted index
- vectorized using SIMD + GPU
- cache, material CTE
MySQL
-
- WHERE Clause Optimization
- 移除不必要的括号 (表达式优化)
- Constant folding
(a<b AND b=c) AND a=5->b>5 AND b=c AND a=5 - Constant condition removal.
- count(*) 优化
- 在没有 group by 时, having 合并到 WHERE 中
- where 下沉到 join 表
- constant tables 提前读取
- join 顺序:如果 order by / group by 字段来源于单个表,则这表优化。
- Range Optimization
- Window Function Optimization
- 如果子查询具有窗口函数,则禁用子查询的派生表合并。子查询总是具体化的。
- 半连接不适用于窗口函数优化,因为半连接适用于 WHERE和中的子查询JOIN ... ON,其中不能包含窗口函数。
- 优化器按顺序处理具有相同排序要求的多个窗口,因此可以跳过第一个窗口之后的排序。
- 优化器不会尝试合并可以在单个步骤中评估的窗口(例如,当多个 OVER子句包含相同的窗口定义时)。 解决方法是在子句中定义窗口并在 WINDOW子句中引用窗口名称OVER。
- WHERE Clause Optimization
-
- subquery: scalar subquery, 1-row subquery, or N-rows subquery
- derived table
select ... from (subquery) as tblorselect * from JSON_TABLE(arg_list) as tbl - view reference
- Common Table Expression
优化策略:
IN, = NAY, EXISTSsubquery => Semijoin / materialization / Exists-StrategyNOT IN, <> ALL, NOT EXITSsubquery=> materialization / Exists-Strategy- derived table, view, CTE => merge into query / material
- Semi-join 优化:将子查询转化为 Semi-Join, 如果子查询使用了 range 操作,是无法进行改优化的。
- 物化:当子查询没有引用外部表的字段时,是可以物化的
- (a, b, c) IN (select ... ) 转化为 exists (select ... where ...)
- Merging: 在 Mergeing 后再进行化简,避免一次重复的子查询。
- Condition pushdown:将查询条件下压到 CTE。
- 如果都不能走上述优化,则可能按需执行,在 select 部分,会对美航执行子查询,因而会出现性能问题。
ClickHouse
-
- hash, parallel hash
- grace hash: right table 过大时,将 hashtable 拆分为多个,每次仅在内存中存放一个分区,其他放到磁盘保存。
- full sorting merge: 左表、右表都在关联字段上排序
- partial merge:右表在关联字段上排序。
- direct: 类似于 Hash,针对于特定的存储引擎类型。
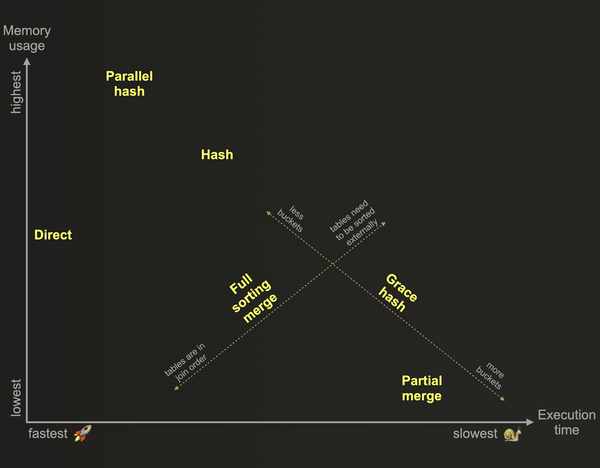
- Join Types supported in ClickHouse
- Hash Join, Parallel HashJoin, Grace HashJoin
- Full Sort Merge, Partial Merge Jooin
从文档上看,如果右表已经是排序的,也需要做一次排序,感觉这个是多余的
- Direct Join
Subquery 优化
-
left join
SELECT o_orderkey, ( SELECT c_name FROM CUSTOMER WHERE c_custkey = o_custkey ) AS c_name FROM ORDERS; SELECT o_orderkey, c_name FROM orders left join customers on c_custkey = o_custkey -
semi join
SELECT c_custkey FROM CUSTOMER WHERE c_nationkey = 86 AND EXISTS( SELECT * FROM ORDERS WHERE o_custkey = c_custkey ) select c_custkey from customer semi join orders on o_custkey = c_custkey where _nationkey = 86 -
group by
SELECT c_custkey FROM CUSTOMER WHERE 1000000 < ( SELECT SUM(o_totalprice) FROM ORDERS WHERE o_custkey = c_custkey ); SELECT c_custkey, SUM(o_totalprice) From customer left join orders on o_custkey = c_custkey group by c_custkey having 1000000 < SUM(o_totalprice) -
集合比较
SELECT c_name FROM CUSTOMER WHERE c_nationkey <> ALL (SELECT s_nationkey FROM SUPPLIER); select c_name from customer anti semi join supplier on c_nationkey = s_nationkey;