实例讲解 Java 内存模型
实例讲解 Java 内存模型
Java内存模型(JMM)是一个相对抽象、高级的话题,相关的规范在Memory Model有详细的定义。JMM主要解决内存读写的可见性问题。
那么,什么是内存读写的可见性问题呢?会出现什么样的问题,如何解决这些问题呢?本文讲试图通过一些实例来讲述。
反例代码
首先,我们来看一段代码:
import java.util.concurrent.BrokenBarrierException;
import java.util.concurrent.CyclicBarrier;
public class Test2 {
int a = 0;
int b = 0;
int x = -1;
int y = -1;
public void path1(){
a = 1;
x = b;
}
public void path2(){
b = 2;
y = a;
}
public boolean test() throws InterruptedException {
a = b = 0;
x = y = -1;
CyclicBarrier barrier = new CyclicBarrier(2);
Thread t1 = new Thread(){
public void run() {
try {
barrier.await();
path1();
} catch (InterruptedException | BrokenBarrierException e) {
}
};
};
Thread t2 = new Thread(){
public void run() {
try {
barrier.await();
path2();
} catch (InterruptedException | BrokenBarrierException e) {
}
};
};
t1.start();
t2.start();
t1.join();
t2.join();
if(x == 0 && y == 0)
return false;
else return true;
}
public static void main(String[] args) throws InterruptedException {
for(int i = 0; i< 1000*1000; i++){
if(new Test2().test()==false) {
System.out.println("found on " + i);
}
}
}
}
这个例子,初始化时,a = 0, b = 0, x = -1, y = -1, 启动两个线程,分别同时执行 path1 和 path2,
那么在2个线程执行完成后,是否可能会出现 x == 0 && y == 0 的情况呢?

现在让我们来模拟一下可能的执行情况:
- Thread 1 的 a = 1 先于 Thread 2 的 b = 2 执行。如下图
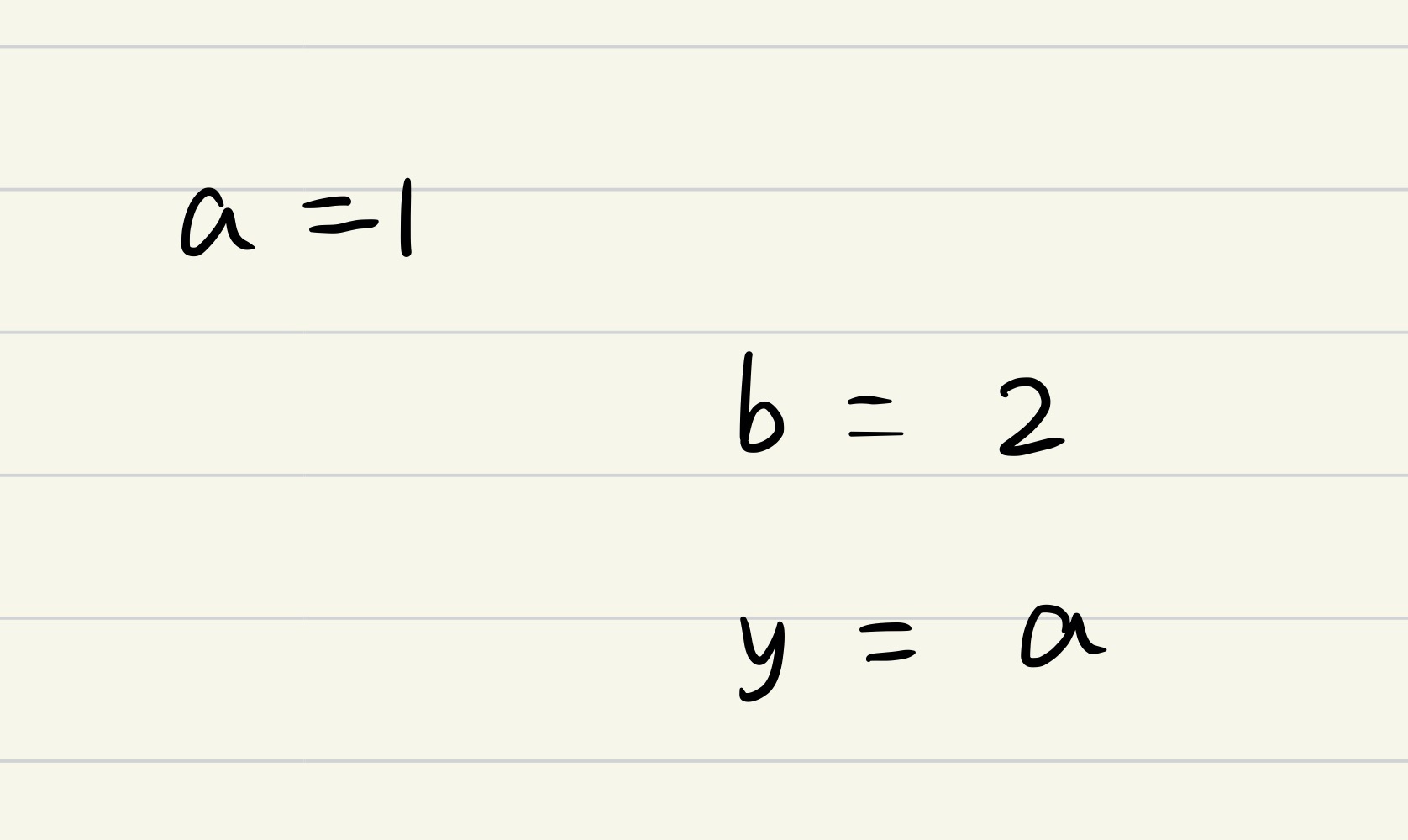
在这种情况下, y = 1, x 可能为0或者2。 不会出现 y == 0 && x == 0的情况。 - Thread 1 的 a = 1 晚于 Thread 2 的 b = 2 执行,如下图:
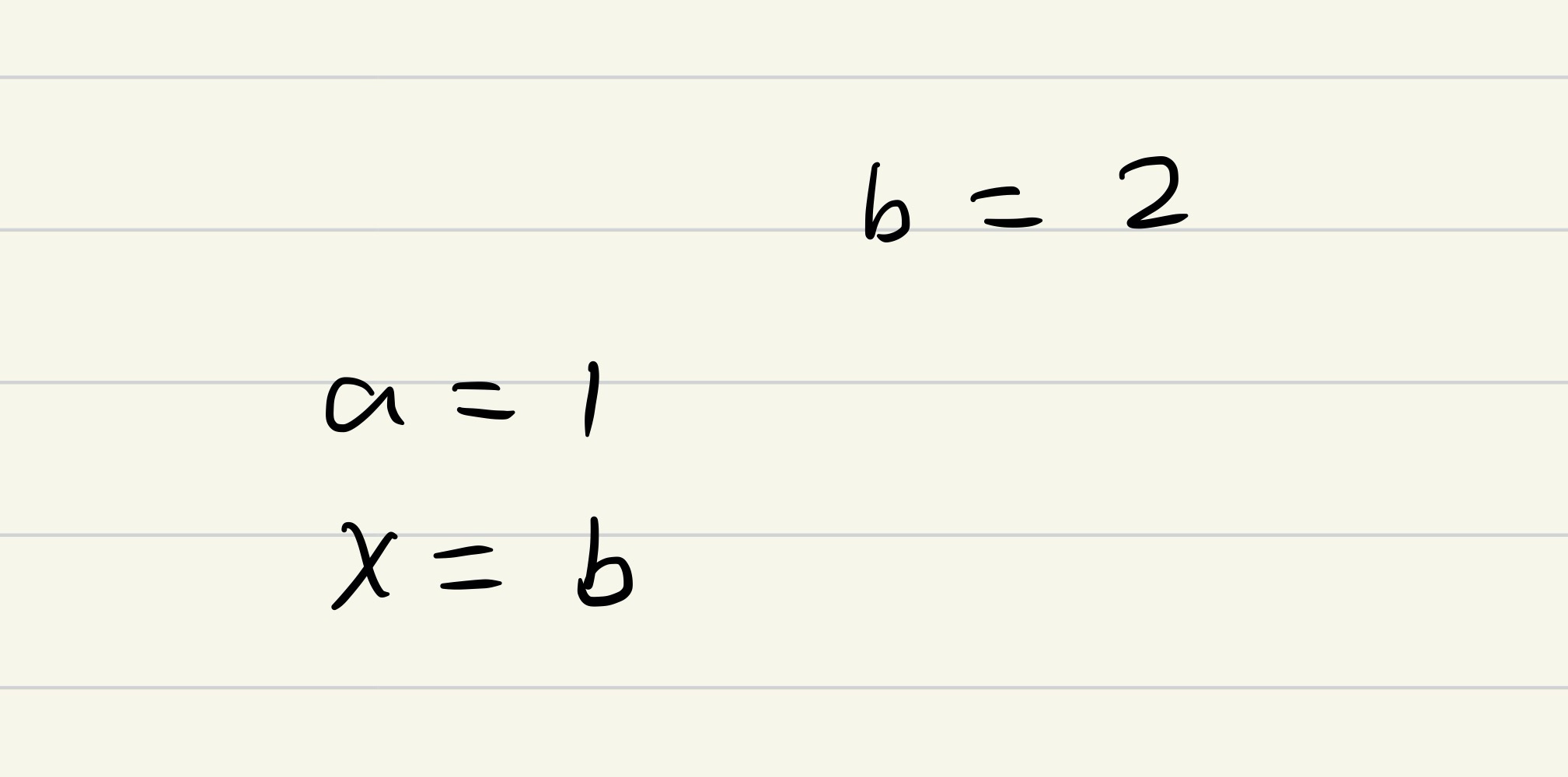 在这种情况下, x = 2, y 可能为 0或者1。不会出现 x == 0 && y == 0的情况。
在这种情况下, x = 2, y 可能为 0或者1。不会出现 x == 0 && y == 0的情况。 - Thread 1 和 Thread 2 完全同时执行。
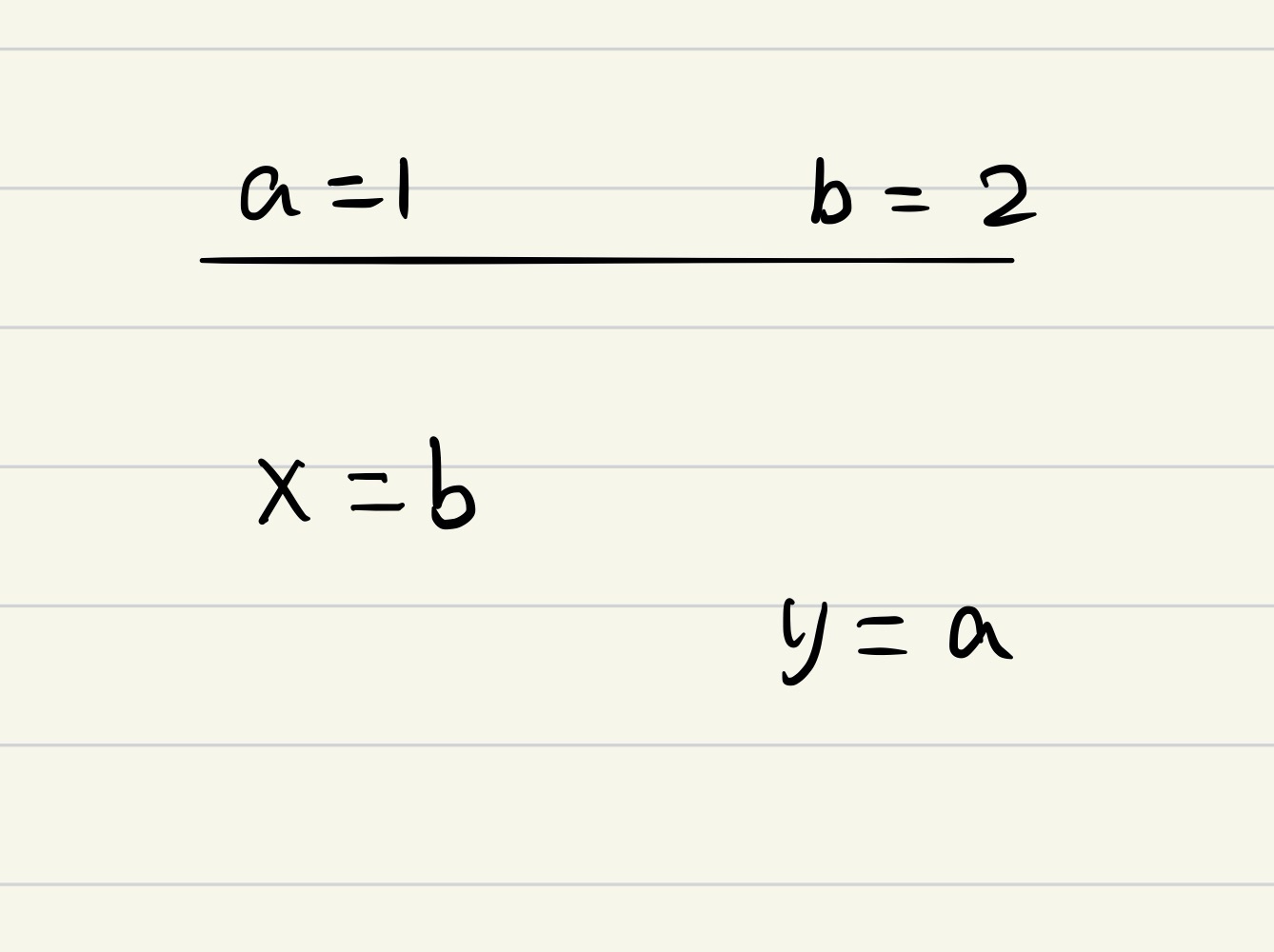 在这种情况下, x = 2, y = 1,不可能出现 x == 0 && y == 0 的情况。
在这种情况下, x = 2, y = 1,不可能出现 x == 0 && y == 0 的情况。
根据我们的分析,无论是 T1先于T2,T1晚于T2,还是 T1,T2完全同时执行,理论上都不会出现 x == 0 and y == 0 的情况出现。
但是实际上,我们去运行上述的代码,却可能会出现违背预期的情况。
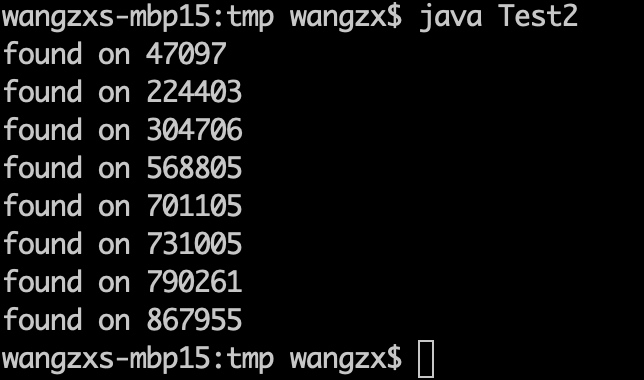
在我的MacBookPro上,执行上述代码,在1百万次循环中,出现了8次不符合“预期”的情况。虽然说,这种几率是非常低的,百万分之八。但这样的问题如果出现在线上系统中,每天都出现数次或者数十次异常情况,会是一件非常令人抓狂的事情。
原因是什么?
我们上面分析了3种可能的执行路径,“理论”上,是不会出现x,y同时为0的情况的,但实际执行结果并不符合预期。肯定是我们的分析出了问题。CPU的实际执行,和我们上面的“假设”并不一致。
实际上,我们上面分析的三种可能的执行路径,都有一个基本的假设:CPU 是先执行上一条指令,然后在执行下一条指令,且执行完这条指令后,执行结果,可以在其他的CPU(线程)上反映其执行结果,即:
- 在同一个线程内,CPU是依照顺序执行指令的。
- 当前CPU执行完一条存储指令后,在其他CPU上读取该地址时,可以马上读取到我们写入的结果。(当然,也隐含着:当前CPU可以马上看到写入的结果)。
这两个假设,都是比较符合我们的理解逻辑的,这才是正确反映我们代码逻辑的方式。事实上,如果CPU严格的按照上述逻辑来执行代码,是不会出现上面的异常情况的,但不幸的是,这两个假设,在现代大部分的CPU上都不成立。本文就以我们最熟悉的 x86 系列CPU来进行说明。
-
在同一个线程内,CPU 是按照顺序执行指令的。 实际上,X86 不再完全遵守顺序执行指令的原则。X86 采用多级流水线架构,CPU可以在同一个时钟周期内,解码多条指令,并同时发射到多个执行单元进行执行,这称之为“多发射”技术。采用多发射技术,CPU可以在同一个时钟周期内同时执行多条指令,这使得程序执行速度变得更快了。 当然,要进行这种优化,也是有前提条件的,比如,如果两条指令存在依赖关系,那么,CPU是不能将其同时执行的。
a = x b = a + 1Intel曾经设计过一款名为 Itanium(安腾) 的CPU,这款CPU容许编译器显式的将多条指令合并成为1条宽指令,交给 CPU 执行,从而实现更好的性能。可惜的是,这款处理器,从来就没有占领市场,目前已经被Intel抛弃了。 目前的 X86 架构,采用的是由 CPU 自己来管理指令的依赖关系,并采用多发射的方式,来实现性能提升,其实也间接实现了 Itanium 未达成的使命。而且,无需编译器进行革命性的改变。
-
当前 CPU 执行完一条存储(写入内存)指令后,在其他CPU上可以马上读取到其结果。 实际上,X86 并不提供这种承诺。假设CPU要提供这种承诺,则意味着:当前的存储指令,必须等待到实际将数据真实写入到内存中。考虑到 CPU 访问内存的速度相对于CPU的自身的执行速度而言,是相当缓慢的。
- Register:1 Cycle
- L1 Cache:3 Cycles
- L2 Cache:10+ Cycles
- L3 Cache:20~30+ Cycles
- Main Memory:~100 Cycles
考虑到大部分的CPU计算,都可以在1个周期内完成,也就是说,如果等待一次内存的访问,可能会浪费掉100条执行的执行能力。 所以,实际上,CPU会对内存的读写进行大量负责的优化:
- 引入 L1,L2,L3 Cache。
- 引入 Write Buffer。 这是一个比较复杂的过程,本文不对此进展展开,这里阐述的是这样的一个事实:当CPU执行完一个 Store 指令时,为了保证最佳的CPU执行效率,它并不保证数据已经写入到主存中,它可能是写入到当前CPU的一个内部 write buffer中,然后再合并,写入到 L1 Cache、L2 Cache、L3 Cache、Main Memory中。这里 L1, L2是每个CPU私有的缓存,L3 Cache是多个CPU 所共享的。 当写入数据在 Write Buffer 时,其它CPU读取数据时,依然会读取到之前的值。而当数据已经写入 L1/L2 Cache时,X86会通过缓存一致性协议,确保其它的CPU读取到更新后的值。所以,在数据从write buffer写入到Cache之前,其它CPU是无法读取当前线程的写入结果的。
那么,在什么情况下,会出现 x == 0 && y == 0 呢?

- [a] = 1 和 r1 = [b] 指令没有依赖关系,可以同时执行.
- [a] = 1 是一条Store指令,其数据会先写入CPU的 WriteBuf,然后写入 Cache,大约需要 3+ 时钟周期,为其它线程所能读取到。
- r1 = [b] 是一个Load指令,其数据可能已经在 L1 内,可以立即执行,其值为0
- [b] = 2 和 r1 = [a] 指令没有依赖关系,可以同时执行
- [b] = 2 是一条 Store 指令,其数据会先写入 CPU 的 WriteBuf,然后写入 Cache,大约需要 3+ 时间周期之后,其它线程才能读取到写入的值。
- r1 = [a] 是一条 Load 指令,其数据可能已经在 L1 内,可以立即执行,其值为0. 当出现这种执行路径时,就会出现 x == y == 0的情况了。
综上,[a] = 1 和 r1 = [b] 这两条指令,其执行的结果相当于重新排序了: r1 = [b], [a] = 1。这里说的重排序,是指在其它CPU的视角来看,两条指令的执行顺序。在执行CPU 自身来看,是不存在重排序的问题的,CPU 的优化总是保证符合单线程的语义不变的。
四种重排序
上面的示例实际上是一次 Store - Load 的重排序,一共有四种形式的重排序:
- Load - Load
- Store - Store
- Load - Store
- Store - Load
不同的CPU有不同的指令重排序策略,而在X86中,只有 Store Load 是会出现重排序的,而其它的三种: Load Load, Load Store, Store Store 都不会出现重排序。
- Load Load, Store Store 不会重排序。

- 如果 r1 = 1, 则意味着 [y] = 1 已执行, 则 [x] = 1 必然已执行
- r2 = [x] 必须晚于 r1 = [y],因此,r2 一定等于1
- Load Store 不会重排序

- 如果 r1 == 1,则意味着 [x] = 1 已经执行,由于 Load Store 不能重排序, r2 = [y] = 0
- 如果 r2 == 1, 则意味 [y] = 1已经执行,此时 r1 = [x] = 0。
- Store Load 可能会出现重排序。这个已经在上面的案列中说明。
对其他的CPU,如Arm,可能会有不同的指令重排序限制,具体情况如何,作者对Arm不熟悉,没找搜集到这方面的资料。
防止重排序
为了防止内存重排序,我们可以在 指令和指令之间插入一些特定的指令,来防止重排序。这些指令称之为 memory barriers, 或者 memory fence。有四种类型的内存屏障。
- LoadLoad. Load1 LoadLoad Load2 在两条 Load指令之间插入 LoadLoad,可以确保两条Load指令不被重排序。对X86来说,不需要 LoadLoad 屏障。
- StoreStore Store1 StoreStore Store2 在两条 Store 指令之间插入 StoreStore,可以确保两条 Store 指令不被重排序。对 X86来说,不需要 StoreStore屏障。
- LoadStore Load1 LoadStore Store2 在Load和Store指令之间插入 LoadStore,可以确保Load1 Store2指令不被重拍讯。对X86来说,不需要 Load Store指令。
- StoreLoad Store1 StoreLoad Load2 在 Store1和Load2之间插入 StoreLoad,可以精致 StoreLoad 重排序。这是 X86 所需要的。X86 提供 sfence, lfence, mfence 三种内存屏障指令。
volatile
lock addl $0, [esp]
putOrderedLong
putLongVolatile
引述:《Intel 64 and IA-32 Architectures》8.2.3 Examples Illustrating the Memory-Ordering Principles 一文。
讲述内容:
- volatile 对 JavaC 的影响。
- volatile 对 JVM 的影响
- unsafe.putOrderedLong 是什么意思
- What's happen-before and memory-oder? 能给我一个反例吗?
- write back
- write through
Store-Store, Load-Load not reordered
Load-Store not reordered
Store-Load maybe reordered.
这个案例和 DCL 是相同的概念的。
package demo;
import java.util.Queue;
import java.util.concurrent.BlockingDeque;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;
public class Test1 {
// Thread1
// Thread2
// thread submit a req and waiting a response
// thread2 process req and subit a response
BlockingQueue<Task> queue = new LinkedBlockingQueue<>(100);
class Task {
String request;
String response;
}
class Consumer extends Thread {
public Consumer(){
setDaemon(true);
}
@Override
public void run() {
while(true){
try {
Task task = queue.take();
task.response = task.request.toUpperCase();
synchronized (task) {
task.notify();
}
}
catch(InterruptedException ex){
ex.printStackTrace();
}
}
}
}
class Producer extends Thread {
@Override
public void run() {
int count = 0;
while(true){
Task task = new Task();
task.request = "Hello";
queue.offer(task);
synchronized (task){
if(task.response == null) {
try {
task.wait(60_000);
}
catch(InterruptedException ex){
}
}
}
if(task.response == null){ // do volatile required?
System.out.println("reponse is null at " + count);
System.exit(1);
break;
}
count += 1;
if(count % 1000_000 == 0) {
System.out.println("runs " + count/1000_000 + "M turns");
}
}
}
}
void runTest(){
new Producer().start();
new Producer().start();
new Producer().start();
new Producer().start();
new Consumer().start();
new Consumer().start();
}
public static void main(String[] args) {
new Test1().runTest();
}
}
后记
2025-04-07 学习《超标量处理器设计》,对CPU ISA(微架构)有一定理解后,可以更好的理解这个问题
- 对超标量处理器、多发射、乱序执行情况下,理论上指令从前端解码后,会进入到后端发射队列。此后,其执行是乱序的。可能会出现后面的指令先执行, 前面的指令后执行的情况。
- ROB(Reorder Buffer) 乱序执行的指令,可能会在ROB中等待很长时间,才会被提交到内存中。这个主要是对单个线程的有序性而言,主要是针对应用可见的寄存器、内存的可见性而言。
- 在执行指令时的内存有序性,存在 Load-Load, Store-Store, Load-Store, Store-Load 四种情况。不同的 CPU 架构有不同的实现。
- x86 架构下,Load-Load, Store-Store 不会重排序,Load-Store 不会重排序,Store-Load 可能会重排序。
- ARM 架构下,都会出现重排序,需要显示使用内存屏障。优点是容许更多的指令重排,从而提升 IPC,但并发场景中需要更多的内存屏障。
Load-Load (这个案例待改进)
// 共享变量
int data = 0;
bool ready = false;
// Thread A: 写入数据
void writer() {
data = 42; // 写操作
ready = true; // 写标记
}
// Thread B: 读取数据
void reader() {
while (!ready) { /* 等待 */ }
int local_data_1 = data; // Load 1
int local_data_2 = data; // Load 2
assert(local_data_1 == local_data_2); // 断言应总成立
}
Store-Store
// 共享变量
int a = 0;
int b = 0;
// Thread A: 写入两个变量
void writer() {
a = 1; // Store 1
b = 2; // Store 2
}
// Thread B: 检查写入顺序
void reader() {
while (b != 2) { /* 等待 */ }
assert(a == 1); // 若 Store-Store 重排导致 b=2 先于 a=1,则断言失败
}
Load-Store(此案例待改进)
// 共享变量
int data = 0;
bool ready = false;
// Thread A: 写入数据
void writer() {
data = 42;
ready = true; // 写标记
}
// Thread B: 读取数据后立即写入新值
void reader() {
while (!ready) { /* 等待 */ }
int local_data = data; // Load
DMB(LD); // 假设此处缺少屏障
data = local_data + 1; // Store
}