关于软件复杂性
复杂性是软件开发中最为核心的问题,绝大多数的创新,包括方法论、工具、框架、编程语言等,都可以说是为了应对复杂性的挑战而产生的。众多软件产品、 项目往往消耗巨大的人力、财力,在解决项目中因复杂性带来的维护、BUG、安全问题上。本文收集了一些关于软件复杂性的观点,并叠加了一些个人的思考。
本文主要参考:
- A Philosophy of Software Design 中文版:软件设计的哲学
- Chapter 2: The Nature of Complexity
- The Art of UNIX Programming 中文版:Unix编程艺术 (微信读书上有电子书)
- Chapter 13: Complexity, As Simple As Possible, but No Simpler.
- Rust for Rustaceans
- Chapter 3: Design Interfaces
1. 复杂性
复杂性的定义
在软件设计的哲学一书中,对复杂性进行了如下定义:软件的复杂性是指那些让系统难以理解的部份:
- 难以理解:当出现问题时,难以找到问题的原因,对系统的行为难以预测。
- 难以修改:无论是添加新功能、修复BUG、优化性能,无从下手,改不动,或者修改完后引入更多的问题。
这两个问题是相互关联的,因为难以理解(无法理解其结构、流程、算法),会导致难以修改。而因为难以修改,会导致在维护的过程中,引入更多的补丁,导致 系统更为复杂,可理解能力持续下降。
复杂性的主要症状
-
变更放大:对系统的一个小变更,会导致系统中的多个地方进行修改,例如,在一个网站中,修改 banner 的内容、颜色,可能会导致多个页面的修改。
- 根源之一:重复。多个模块存在相同、相似的逻辑。当存在重复的代码、逻辑时,修改就会蔓延。
- 根源之二:耦合:当一个模块发生变更时,会辐射到其他模块,然后继续辐射,最后形成一个巨大的变更范围。
Macro 是应对重复代码的一种方式。
-
认知负荷:开发人员需要掌握多少知识,才能完成一个任务(例如调用接口、完成某个功能)。理论上,每个功能的实现,深究下去,就会涉及到计算机科学的 各个领域,例如:操作系统、网络、数据库、编译原理、算法等,可以制造出无穷的复杂性。
- 根源之一:缺少封装,暴露了太多的细节,加深了外部的认知负担。
- 根源之二:缺少抽象。把众多功能特性混合在一起,构成一个 macro 模块。
- 根源之三:不一致性。 对软件产品而言,UI、文档的不一致性会带给用户认知负担。对软件代码而言,命名、接口、行为的不一致性性,会带给维护人员 理解代码的认知负担。不一致性与重复是密切相关的,重复会带来不一致性。
- 根源之四:不符合直觉、惯例的设计。每个语言、框架,都有其自己形成的惯用法,最佳实践。
-
未知的未知(不确定性)。在庞大的认知负荷之下,是不确定性。
- 缺乏契约定义(边界不明确):对输入、输出的边界、约束、规范没有明确的定义。
- 语义不清晰。接口的行为,讲不清楚,自然实现就考虑不到,也无法进行测试覆盖。
- 不可证明性。
- 不完备性。系统的行为是否能覆盖契约(边界内)的全部场景,有哪些不能覆盖的场景是未知的。
复杂性的分类
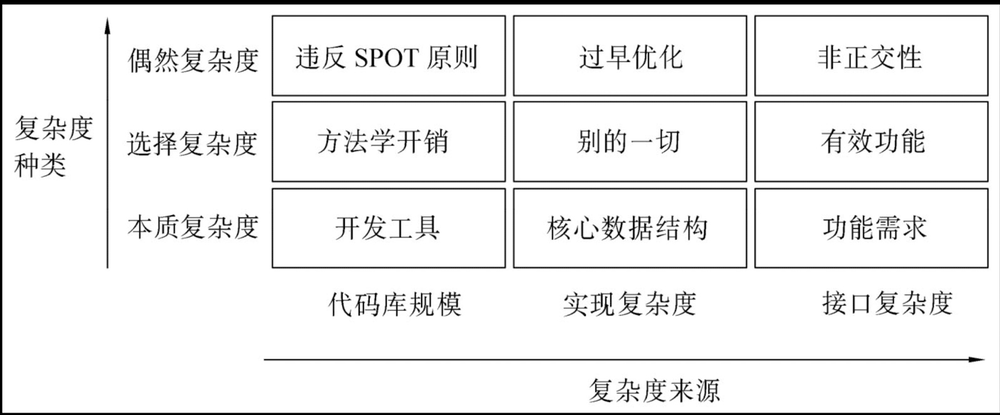
在UNIX编程艺术一书中,将复杂度分为3类、3个来源:
-
复杂度种类:
- 本质复杂度:问题领域自身的复杂性。
- 选择复杂度:与目标需求相关的复杂性,只能通过改变工程的目标来改变复杂度。
- 偶然复杂度:可以通过良好的设计、过程来改善的复杂度。
-
复杂度来源之一:代码复杂度:
UNIX编程艺术一书中,认为:"代码的缺陷密度,每百行代码出错率,往往是一个与实现语言种类无关的常量。更多行的代码意味着更多的 bug, 而调试常常是开发中最昂贵、最耗时的部分。",这种说法放到今天,我觉得是不正确的了:代码行数仅是复杂度的一个指标,但相同行数的代码,仍然会有不同的复杂度,甚至差异很大。例如圈复杂度,加入了对分支路径的 复杂度评估。在这方面,函数式编程语言(如Scala) 相比 过程式编程语言(Java)来说,有着显著的优势。
- 代码行数
- 圈复杂度(分支、路径):FP 通过高阶函数减少了分支,降低了数据复杂度。
- 数据流复杂度。FP 的数据不变性,形成了 SSA(Static Single Assignment) 形式,降低了数据流复杂度。
- 功能密度:更高级的语言、更良好的抽象,也会带来更高的功能密度。一行代码就可以等效于低级语言、低级抽象的多行代码。
-
复杂度来源之二、之三: 接口复杂度/实现复杂度
-
MIT / New Jersey 风格
UNIX编程艺术一书中提到的 MIT 哲学,侧重于 接口的简单性,而 "New Jersey" 哲学,则侧重于实现的简单性。书中也提到 UNIX 的哲学是偏向于 接口的简单性,以及处理 signal 的风格,System V 则是偏向于实现的简单性,而 BSD 偏重于接口的简单性。 -
Simple vs Easy Executable Pseudocode that's Easy, Boring, and Fast
- 可执行的伪代码。核心就是面向阅读的高可阅读性的代码。需要经常挑战的是:要完成这段功能,还可以更简单吗?
- Easy not simple: 这里 Easy 是对使用者而言的。接口简单,才能让使用者更容易使用,simple 是对实现者而言的。
- Boring not interesting: 作者的意思是不要搞大而全的框架,而是聚焦于一个领域,做好一个小而美的工具。
早期教条的 UNIX 哲学:宁可放弃功能,也不能放弃简单性。 CLI 与 GUI 之战,就是这种哲学的体现。这也是典型的“因为脏水而丢掉孩子”的做法。
软件设计的哲学一书中列举了 ed、vi、sam、emacs、wily 等文本编辑器的演进历程。软件设计的哲学一书中,更是提出了 “Deep Module” 的设置哲学,即强调:- 接口设计应当 smaller and simpler,从而减少依赖复杂度,认知复杂度。
- 模块内部的实现,应该 deep,即包含更多的功能,隐藏更多的细节。而避免 proxy/adapter 这种浅层模块。
-
复杂性的度量
待补充
2 如何降低接口复杂性
2.1 Design By Contract: 增强接口的确定性
设计契约(Design by Contract)是一种软件设计方法,由 Bertrand Meyer 在 1986 年提出。Meyer 甚至创建了一门语言:Eiffel。Eiffel 语言的最大特征 就是内置了对 Contract 的支持,将 DBC 从约定变为显式的编程构件。
note
description: "Simple bank accounts"
class
ACCOUNT
feature -- Access
balance: INTEGER
-- Current balance
deposit_count: INTEGER
-- Number of deposits made since opening
do
... As before ...
end
feature -- Element change
deposit (sum: INTEGER)
-- Add `sum' to account.
require
non_negative: sum >= 0
do
... As before ...
ensure
one_more_deposit: deposit_count = old deposit_count + 1
updated: balance = old balance + sum
end
feature {NONE} -- Implementation
all_deposits: DEPOSIT_LIST
-- List of deposits since account's opening.
invariant
consistent_balance: (all_deposits /= Void) implies
(balance = all_deposits . total)
zero_if_no_deposits: (all_deposits = Void) implies
(balance = 0)
end -- class ACCOUNT
DBC 只要由三个部份组成:
- 前置检查:一般是接口调用者需要保障的部份(调用者的职责)。当然,对于很多服务处理来说,前置检查也成为是服务提供者的责任。不过,一些基本的类型层面 的检查,更加建议直接通过强类型的方式来实现,在框架层进行检查,避免让服务提供者处理这类低层次的检查工作。
- 后置检查。后置检查是服务提供者在完成服务处理后,所需进行的必要检查,确保自身处理的正确性。
- 不变量。不变量是一类对象的基础契约,无论进行何种操作,都不应该破坏这种契约。
现在,主流的编程语言,都没有对 DBC 的语言级显示支持,而改为使用 assert 机制来提供部份的 DBC 能力。作为接口设计的一部份,为接口(方法、对象)提供 明确的契约定义,这应该成为设计的一部份:具备清晰、良好的契约定义的接口、对象,会有更加确定的边界。而反之,缺乏契约定义的接口、对象,很可能会产出 不清晰的职责、不确定的边界,以及在 life time 中产生脏数据,从而使得后续的行为变得更为不可琢磨。
以 RDBMS 为例,其提供了 table/column 级上的很多 constraint:
- unique index 保证了数据的唯一性,防止重复数据。
- not null 防止 null 数据进入。
- check 约束,保证数据的合法性。部份数据库可以定义一些列上的校验表达式。如
CHECK (AGE >= 18) - foreign key:引用完整性。
在能使用这些场景的地方,应该优先使用数据库的约束,而不是在应用层进行约束。不过,对很多互联网应用来说,由于分库分表等物理部署的约束,会限制使用 foreign key,那么也需要在应用层有相应的应对措施,避免脏数据进入系统。脏数据进入系统,本身就以为着系统存在严重的 bug,更会导致后续复杂的处理、 以及带来更多不确定的 BUG,从而使得复杂性恶化,是需要尽可能提前治理的。
Contract
- 可以作为文档的一部份,为接口的使用者提供价值,
- 可以作为测试的一部份,在测试阶段、试运行阶段,作为接口的内部保护器。
- 如果不是性能关切的,应该在运行期间进行必要的契约检查。如果某些契约检查有较高的性能成本,则可以考虑异步、批量的方式进行。
2.2 外向设计(面向使用者的设计)
对接口设计 和 模块实现之间的平衡和取舍,有两种说法是很生动、有趣的:
- 一个糟糕的实现,如果隐藏在一个良好的接口后面,这个糟糕的实现是可以接受的。(这也是敏捷、迭代、TDD、prototype 等方法论的基础)
- 软件设计应该是外向的(面对使用者进行设计),而不是内向的(面向实现细节进行设计):把简单(Easy)留给用户,把复杂(Complex)留给自己。
- UI(User Interface) 与 API(Application Programming Interface) 两者都是 interface,其设计哲学有诸多相似之处。
我在实际工作中,看到的大部份的开发者,总是习惯于内向的风格:我要如何实现这个功能。这样做会设计出糟糕的接口(缺乏抽象、使用不方便),进而又 导致内部模块的抽象度不够(做一个好的抽象是有难度的,内向的设计风格会使得我们先避开局部的复杂性,而简化接口),导致实现的整体复杂度增加。而 转为外向的风格时,我们会优先从使用者的角度来设计接口,让接口更为简单、自然、清晰。这需要更多的抽象,也需要考虑更多宏观的问题。TDD 就是一种外向 的设计风格。
对实现的复杂度,我们可以:
- 通过迭代的方式来实现,在前期,先实现一个简单的版本,或者某个原型实现。
- 在后续迭代中,逐步深化抽象、分拆化、正交化,将复杂度逐步降低。
随着技术的演进,今天需要转移到调用者的复杂性,未来可能会变得简单。例如,异步处理的方式,就从最早的 callback 模式,演进到 Future/Promise, 再到 async/await 模式,每一步都是将复杂性从调用者转移到实现者。
当然,在有的时候,平衡是必须的:
-
接口设计的简单性,并不是一件容易的事情,需要有很好的抽象能力。有时这种能力必须建立在目标领域的深入理解、丰富经验之上。在对目标领域不够理解 的情况下,很难做出简单、优雅的接口设计。 所以,有时,还是需要快速前进,等踩了坑之后,你才会知道正确的设计是什么。
-
在部份场景下,接口的简单性会带来过高成本的实现复杂度(可能是受当前的技术、资源限制,难以突破),或者追求接口的简单性,会带来严重的性能损失, 在这种情况下,做必要的妥协是有价值的。(
UNIX编程艺术一书中列举了系统调用中对无法屏蔽的中断的处理方式,以及 www 中对 404-Not Found 的处理方式 就是将一定的复杂性从实现者转移到调用者去的很好案例。)
2.3 一些接口设计的原则
本节内容参考 RustforRustaceans 一书第3章:Design Interfaces,是对本章内容的一个很好的注脚。
-
Unsurprising: 降低认知负荷。已经形成的惯例(idiom)、习惯的命名、基础类型(common traits)设计模式、风格,自身的合理性得到了时间的检验, 也因为更多的人熟悉、更丰富的文档、 更多的使用案列而减少认知负荷。
已有的管理、模式并非不能打破,但打破时,需要有充分的理由,而不是为了追求新奇。如果你不了解、不理解已有的模式,那么所谓的创新,很可能是低水平的 重复,既没有提供新的价值,又增加了认知负荷。
-
Flexible: 设计一些通用的接口,提高代码的可复用性。基于接口,而非具体实现,使用 generic, 使用更具抽象的类型,而非具体化类型,从而增加接口的灵活性。 很多语言都为 Flexible 提供了支持,例如:Rust 的 trait, Java 的 interface, C++ 的 template, Scala的 Context Bound 等。
-
Obvious: 通过注释、文档、类型体系、都可以提供更为明确的接口信息,从而降低认知负荷。
-
Constrainted:提高确定性。强类型体系、前置条件,后置条件,不变量、断言等,对接口进行约束,提高了接口的确定性。
DBC(Design by Contract) 就是特别针对 Constrainted 的一种设计方法。有良好 DBC 实践的设计一般都会有更好的质量。
3. 拆分:降低实现复杂度
排序算法是很有意思的算法,从最简单的冒泡排序 O(n^2) 到快速排序 O(n log(n)),其中的核心思想就是分拆,将一个大的问题分拆成小的问题,然后再组合。 在这里,当问题分解到足够小时,它就变得简单了(衍生的问题是组合的成本)。软件的复杂性或许也是如此,其复杂度与内部规模的平方成正比,通过分拆后可以转化为 准线性的增长。
拆分的核心都是围绕:解耦、内聚来进行的:减少模块间的耦合,强化模块内的聚合。
三种层次的拆分:
- 模块拆分(包、类、方法):源代码层面
- 组件化:COM 是组件化的经典案例。
- 部署拆分:微服务
一些常见的拆分方法:
- 按照领域拆分(水平拆分):微服务:遵照康威定律,将组织结构映射到系统架构上,将不同的业务功能拆分成不同的服务。
- 按照层次拆分(垂直拆分):前端接口层、业务流程层、业务核心层(原子服务)、数据访问层、数据存储层。
- 业务与技术拆分(基础设施拆分):基础服务、服务治理、数据目录等。
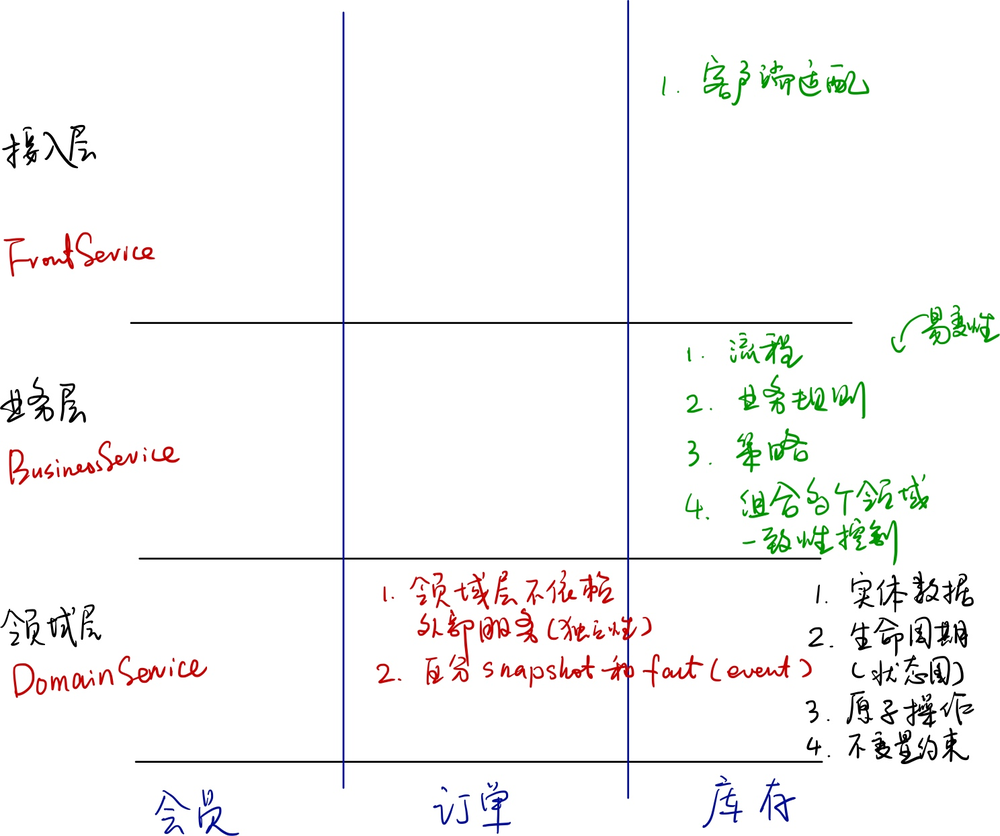 附一张我之前对分层、分领域,易变形相关的思考图。
附一张我之前对分层、分领域,易变形相关的思考图。
3.1 原则:正交化拆分
正交化:将分拆后的模块,在职责上进行正交化,避免重复的职能。正交化的最佳案列之一就是 WEB 的三个模块:
- HTML(DOM):负责内容
- CSS:负责样式
- JavaScript:负责行为
WEB 之前的 WFC/Motif 等应用中, DOM 与 CSS 是高度混合的,我写过那种代码,相比 WEB 的开发方式,代码量要大一个数量级,是非常痛苦的, 大大的限制了 GUI 应用的开发效率。
正交化设计是一种艺术,在UNIX编程艺术中,提到的一个词是 SPOT(Single Point of Truth):
程序员修炼之道(The Pragmatic Programmer) 针对一类特别重要的正交性明确提出了一条原则:不要重复自身 Don't Repeat Yourself,意思 是说:任何一个知识点在系统内部应当有一个唯一、明确、权威的表述。
正交化设计的另外一些场景: 将业务性代码 与 技术性代码(如任务调度、任务编排)等进行正交化。(在我们进行数据处理的 ETL 中, 就应用到这个拆分,从而大大的简化系统),一般的,业务性代码与业务需求之间有直接的映射关系,易变性强,但技术难度并不大,而技术性代码则具有 更好的通用性,可以应用于不同的业务场景,但其技术挑战性高。将这二者进行分拆,整个系统的复杂性就大为降低。
对复杂的系统,我们应该对业务进行抽象,将非业务性的功能从业务中分离出来。
3.2 拆分:业务性功能与技术性功能
在我们的某个开发项目中,涉及到一个 数据ETL 的任务,这里涉及到数据的加工处理,也涉及到多个任务之间的依赖关系处理,再牵涉到一些偏技术性的需求, 诸如并发(关注TPS、RTT指标)、监控、限流、任务取消(取消任务时释放资源)等,一开始整个任务实现得非常复杂,而且,在技术性需求的处理上很难达到预期。
对这个任务而言,本身有两方面的复杂性:
- 业务复杂性:如何正确的处理 ETL 自身。这个是这个任务的重点,有其自有的复杂性(本质复杂度)。
- 技术复杂性:调度、编排、并发、分布式锁、监控、限流、任务取消。单单任务取消这一项,就有很大的技术挑战:因为我们的产品需要适配 30+ 的数据库, 在取消任务时,是否可以终止 SQL 的执行,从而避免这些重的 SQL 操作继续执行。
将这两个复杂度揉在一起,最后会导致显著的复杂性提升,以至于第一版是一个糟糕的实现:既复杂,又难以达成需求目标,通过将业务、技术性需求分离后,两部份 功能都回归到各自的本质复杂度领域,选择合适的解决方案,最终得以简化。
3.3 DSL: 使用 DSL 降低复杂性
对复杂的系统,要善于定义 DSL,建立 Domain Specific Language,使用描述式的语言,来定义 what 而非 how。实际上,DSL 语言本身 就意味着我们完成了对复杂系统的抽象,将复杂的行为转换成了更高阶抽象的描述,从而抓住了复杂之中的本质。大部份的 DSL 语言都是对某个特定复杂 领域的有效抽象:
- SQL:对关系型数据库的操作抽象
- 工作流:对任务编排的抽象
- React/Vue: 通过类 JSX 或 template 的方式,对 UI 进行抽象(注意这里的描述性,而非操作性)。
- Makefile/Maven/SBT/Cargo: 对项目构建的抽象
- IDL: 对接口定义的抽象
- Regular Expression: 对字符串匹配的抽象
如果能够定义出 DSL,并用于描述系统的逻辑行为时,系统的复杂性会大为降低。
3.4 易变性(Volatility)拆分
每个复杂的系统,都有一些部件是易变的:会随着时间、空间的变化而演变,其自身具有不稳定性。一般来说,易变性的部件,是导致系统复杂性提升的重要原因。
- 对 SAAS 类应用,为不同的客户提供不同的功能。例如,零售系统针对不同的业态提供不同的服务模式。
- 对 电商类应用,随着业务模式的改变,会有不同的客户服务策略、营销策略、会员策略等。
- 对 OLAP 类应用,需要接入不同的数据源,面对不同数据源之间对 SQL 支持的差异。
- 对 Dashboard 类应用,需要面对不同的数据展示需求
对这类系统,我们就需要重点关注如何抽象这一类易变性的部件,将其与稳定性的部件进行分拆,从而实现系统的简化,否则就会陷入“Copy + Modify” 的 模式,最终形成多个完全不同的系统,维护成本会大大增加。
在 Right Software 一书中,提到了避免功能性的分解,而是基于易变性的分解。 Design for change
动静分离,以静为干,以动为支。
- 动态流程:基于原子性的操作,将流程的动态部份提取出来,配合脚本引擎(Script)的方式来实现动态流程。script 可能是 effect 或者 pure的。
- 动态规则:引入类似于规则引擎的机制,来解决规则的动态行。一个规则可以简单抽象为一个 f: input -> boolean (pure)
- 动态策略:类似于动态规则, f: input -> output (pure)
引入动态以后,整个系统的复杂性会提升,质量的管控变得更为重要,因应的措施包括:
- 动态治理:包括监控、熔断限流、报表等
- 加强契约化,尤其是 invariants 的管理,防止核心数据出现脏数据。
从复杂性中识别出哪些是稳定的、静态的内容。老子曰:重为轻根,静为躁君。在复杂的系统中,我们需要将那些稳定的、静态的内容提取出来,形成一个稳定 的主干。这一条其实与上一条:易变性拆分是相辅相成的。易变性拆分是将易变的部件提取出来,而动静分离则是将稳定的部件提取出来。
3.5:应用 SOLID 原则进行拆分
SOLID 原则是对软件设计的五个基本原则的总称:
- S: 单一职责原则(Single Responsibility Principle)
- O: 开闭原则(Open-Closed Principle)
- L: 里氏替换原则(Liskov Substitution Principle)
- I: 接口隔离原则(Interface Segregation Principle)
- D: 依赖反转原则(Dependency Inversion Principle)
SOLID 可以作为模块拆分的一个参考。
对降低复杂度的措施,后续持续更新中 ...
4. visibility makes software simplicity
这个话题,我会单独开一个 blog 来讲述。
5. 应用 Functional Programming 降低编程复杂度
治理软件复杂性的一个误区就是高谈设计,而忽视编码。一个广泛的认知是:软件的复杂性主要是架构师、架构设计的问题,只要设计清晰、架构合理,就不会有大 的问题了。这也创造了诸多 PPT 文化:架构图上堆砌着高大上、时髦、新潮的技术名词,再加上丰富多彩的图标设计,但却可能是绣花枕头,败絮其中。在这方面, 传统的基建领域,应该会朴实很多:华丽的架构和艺术性的设计,在基建领域无疑就是一种价值(这一点甚于软件,软件领域第一价值还是功能需求),但好的基建, 材料、工艺、施工、质量控制等都是基础,都是有严格的标准的。相反,在软件领域,对编码的要求和标准就很相差太大了。
5.1 函数式编程具有更高的功能密度。
使用代码的行数来评估代码复杂度,虽然是一个简单的纬度,但仍然具有一定的参考价值。函数式语言,具有更好的抽象能力、更强的函数组合能力(如高阶函数)